

我国人工智能开源创新生态的模式研究与思考
2026-04-30 14:00
来源:中国网·中国发展门户网




中国网/中国发展门户网讯 开源创新凭借其开放协作、敏捷迭代的优势,正加速构建人工智能(AI)从技术研发到产业落地的创新生态。我国虽在开源社区建设、AI大模型(以下简称“大模型”)开发等方面取得了突破性进展,但在生态成熟度、科技创新引领等方面与世界先进水平仍存在一定差距。要实现从开源参与者、贡献者晋级为开源引领者、主导者,仍有诸多重要课题需要解决。
AI开源生态作为数字科技时代的新型知识生产范式,通过开放协作机制重构算法创新、算力协同与数据流通,系统性重塑全球AI技术创新与产业应用的演进路径。根据开放源代码促进会(OSI)的“开源人工智能”框架,AI技术开放范式允许用户在开源许可下自由使用、学习、调整和分享数据、代码、模型架构、权重参数等技术元素。AI开源创新生态与一般软件开源生态的重要不同之处在于技术复杂性、快速迭代性、广泛渗透性和产业牵引性等方面。现有研究围绕开源创新内涵、生态构建等基础问题展开,亦有学者从国际视野、治理机制、技术路径等多元视角开展AI开源创新生态专题研究,部分研究还探讨了AI基础设施建设与开源生态构建的政策建议,为我国AI开源创新生态的研究与实践奠定了理论基础。
本文基于当前我国AI创新生态发展现状及问题,梳理分析国内头部科技企业和科研院所的实践,总结典型发展模式,为应对我国AI开源创新生态的发展难题提供启示和建议。
人工智能开源创新生态发展现状及问题
我国人工智能开源创新生态发展现状
AI开源创新生态的构建需要实现开源生态、技术生态和创新生态三大要素的有机融合,需要综合考虑开源要素、AI技术体系和创新要素的深度协同。通过协同合作、资源共享、利益分配、国际合作及人才培养等机制创新,推动AI开源创新生态达到竞合共生的理想状态。总体来看,目前国内AI开源创新生态三大要素基本具备,且三者之间有一定程度的融合(图1)。
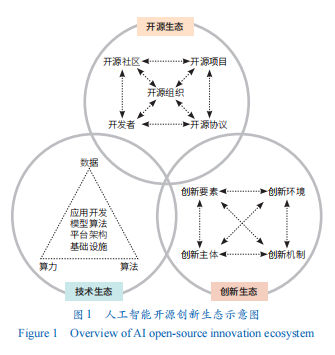
从开源生态来看,开源项目、开源组织、开发者、社区、代码和模型托管平台,以及开源协议等要素相互作用,共同构成并推动开源生态高效运行。随着我国AI开源创新发展政策环境的持续完善,在多方主体共同参与和努力下,我国AI开源生态从无到有、从小到大,逐步迈入良性发展阶段。开源基金会和开源协议完成了“0到1”的突破,国内AI开源社区与开源平台蓬勃发展,呈现出量质齐升的良好态势。自主开源项目与AI开源平台快速崛起,逐步构建起覆盖基础软件框架、开发工具链、AI硬件和协同创新开源平台的AI开源创新生态。
从技术生态来看,以数据、算力和算法为基石的AI技术生态,主要包括数据、算力硬件、云基础设施、工具软件、算法模型、应用开发等方面。相比美国,我国在数据、算力硬件、云计算设施、工具软件等方面依然存在较大差距。数据方面,国际主流大模型训练以英文为主,中文语料占比普遍低于5%。国内发布的中文基础语料和开放数据集,规模和质量仍待提升。算力硬件方面,美国凭借英伟达公司的图形处理器(GPU)及CUDA工具包占据全球近90%的算力市场,并通过出口管制强化壁垒;华为技术有限公司(以下简称“华为”)推出异构计算架构(CANN)并于2025年8月开源,致力于打破AI计算硬件的“碎片化”困境,为多样化的AI处理器提供一个统一、高效、开放的软件基础,但要做好生态协同、社区建设、人才培养等尚需时日。云计算设施方面,美国的云计算公司占据了全球市场近70%的份额;“阿里云”2024年中国市场占有率达到36%,排名国内第1位,但其全球市场份额仅有4%。工具软件方面,中美两国引领了开源贡献,美国以37.4%的贡献领先,中国以18.7%居第2位。算法模型方面,在华为、阿里巴巴集团(以下简称“阿里”)等头部科技企业及北京智谱华章科技股份有限公司(以下简称“智谱”)等新型研发机构的推动下涌现出了昇思(MindSpore)等AI框架,千问(Qwen)、深度求索(DeepSeek)、通用语言模型(GLM)等国际认可度较高的开源基座大模型,技术原生性及自主研发能力有所增强。应用开发方面,DeepSeek凭借其与国外闭源大模型可比的卓越性能和广泛的应用场景,迅速在AI领域占据重要地位,成为技术生态中的重要一环。但总体而言,大模型的开源技术栈的完整性仍有待提升,AI芯片竞争力有待加强。
从创新生态来看,多元参与的创新主体、广泛链接的创新资源、灵活有效的创新机制、开放包容的创新环境是驱动创新生态形成运行的四大核心要素。国内AI开源创新生态基本形成科技领军企业、初创企业、高校院所、新型研发机构及个人开发者等多元创新主体广泛参与,技术(如数据、算法、算力)、人才、资金等创新资源共建互补,协同合作、资源共享等创新机制稳定可靠,共同推动国内AI技术创新突破与创新发展的格局。以北京智源人工智能研究院(以下简称“智源研究院”)、上海人工智能实验室等为代表的新型研发机构快速崛起;作为新一代AI开源创新生态的重要参与者,这些机构兼具“创新主体+创新载体”双重身份,通过组织协作、资源共建等生态机制的创新,探索打造集数据平台、模型算法、产品应用等于一体、覆盖全栈技术的AI开源创新体系。与此同时,新兴科技公司如DeepSeek、月之暗面(Moonshot AI)、智谱等,凭借其技术创新实力和灵活的商业模式,正在为创新生态注入新的活力。
AI开源创新生态的发展方向主要由开源生态、技术生态和创新生态三大体系的融合程度决定。在开源政策的支持和多元创新主体的推动下,我国AI开源创新生态正朝着繁荣共建和深度融合的方向发展。然而,与美国相比,我国开源生态仍存在诸多不足,未来需要在补齐三大生态各自短板的基础上,通过AI、开源和创新三大生态的全面融合,系统性推进AI开源创新生态的建设与完善。
我国人工智能开源创新生态面临的问题与挑战
我国AI开源创新生态建设在稳定性、活跃性、运行机制及国际化等方面依然存在挑战。
稳定性不足
生态共生关系脆弱。当前,我国AI技术与产业均处于快速升级阶段,技术路线与产业需求变化迅速,加剧了生态内部共生关系的不稳定性。同时,开源的“公共属性”与企业的“盈利属性”之间存在根本张力,利益博弈与角色冲突削弱了生态合作的可持续性。
关键要素对外依赖程度高。基础框架层面,国内主流框架多基于PyTorch、TensorFlow等国外生态构建,在底层算子库(如CUDA)、核心计算库(如Numpy)及新兴工具链(如MLIR)上依赖显著。开源平台层面,国内缺乏可与GitHub、Hugging Face媲美的顶极代码托管平台,对国外平台依赖严重。开放原子开源基金会虽承载国家与产业的多重期待,但面对技术快速迭代,其生态支撑能力仍显不足。
AI软硬件生态尚未形成完整支撑体系。国产AI芯片(如寒武纪、昇腾等)的软件栈(工具链、编译器、算子库)成熟度与CUDA等国际主流生态仍有差距,导致开发者适配成本高、应用迁移困难。不同国产硬件厂商的编程接口、加速库等互不兼容,加剧了软件生态的碎片化。从芯片、框架到应用的全国产全栈协同尚未完全构建,制约了异构计算的整体效能。
活跃性欠佳
优质开源人才供给不足。同时具备技术创新力、开放协作力、理解力、实践力的优质开源人才相对有限,尤其是能把开源与企业战略整合进行商业设计的高端人才更是缺乏。开源人才在我国人才培养体系中受重视度偏低,尚未形成“关键运维者—核心贡献者—一般贡献者”结构合理的人才梯队。
开源社区重应用轻基础。国内AI开源项目多集中在应用层,基础设施层项目偏少。在奠定行业标准的PyTorch、TensorFlow等主流框架中,其核心维护团队中来自中国机构的成员占比极低(不足5%),项目演进与技术路线的决策权高度集中于美国开发者手中。中国开发者在AI核心开源项目中的决策参与度严重不足。亟待在核心技术布局与开源生态参与机制上实现突破。
运行机制不成熟
生态协作机制不完善。对开源组织公共价值与治理模式的认知仍显不足,多元主体协同尚未有效形成,“高校—企业—开源组织”间合作链条不通畅,教学科研与开源实践结合薄弱,跨平台协作受到协议不一致、利益分配机制不统一、平台标准不互通等制约限制了生态整体效能。
生态激励和利益分配机制相对滞后。对创新主体生态贡献缺乏全面量化评价,激励方式相对单一。现有贡献评价更多关注技术性贡献,对其过程性和非技术性贡献重视不足,个人开发者激励多以荣誉为主,企业和科研院所等通过开源生态获得的资源反哺、技术和产业转化能力相对有限。
大模型开源的商业闭环尚未形成。开源大模型在技术上取得了显著进展,但商业化的成功案例相对较少。知识产权难以界定,投入产出不确定性巨大。多数开源项目依赖捐赠或资助,侧重于社区建设和技术共享,而不是商业盈利。由于缺乏可持续的盈利途径,仍未形成商业闭环。
国际化程度不高
国际开源组织话语权有限。在国际开源组织治理层,中国代表在关键职位的占比依然偏低(如在LF AI&Data基金会理事会和技术监督委员会的关键职位中占比不到15%),限制了我国引导生态发展方向的能力。
生态外向辐射能力与全球吸引力依然薄弱,国际化程度亟待提升。我国自主开源项目非本土贡献占比相对较低,对全球开发者的吸引力和影响力亟待提升。以DeepSeek为例,海外开发者的贡献占比不足8%,与Hugging Face Transformers超过40%的全球贡献率形成鲜明对比。国内项目在GitHub等国际平台的英文交流比例普遍低于10%,难以有效吸纳全球智慧。
人工智能开源创新生态发展新模式探索
在AI开源创新生态的发展过程中,大型科技公司、初创企业、新型研发机构及开源社区等多元主体通过多样化的实践路径,逐步形成了若干具有代表性的生态构建模式。
平台聚合型开源创新生态模式
平台聚合型开源创新生态依托平台型科技企业强大的全栈技术使能、资源整合能力和用户群体聚集优势,突出平台在整个AI开源创新生态中的核心作用。以阿里为例,平台企业依托全栈AI技术能力快速完成开源创新生态的布局,通过开放普惠算力、开源基座大模型及模型工具集等,充分整合和共享生态资源,降低创新成本,提高创新效率。平台型企业与模型产业链上下游及创新链生态伙伴交互耦合,共同构建形成规模化和平台化的开源创新生态(图2)。
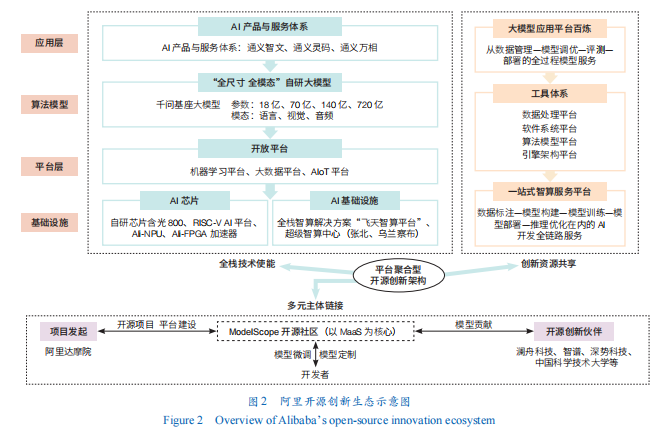
与此同时,阿里以模型即服务(MaaS)理念赋能创新生态发展壮大。阿里通过构建训练及推理平台PAI、开放的模型社区魔塔(ModelScope)、一站式模型服务平台“百炼”等全栈式赋能平台,以模块化技术响应众多初创企业的创新需求。ModelScope社区通过资源的有效整合和共享,降低开发者创新成本,帮助企业和开发者把更多精力专注于应用创新。
技术原生型开源创新生态模式
技术原生型AI开源创新生态以AI关键技术突破为首要任务,以开源生态的自主研发与创新能力提升为目的,旨在通过AI技术及平台资源、项目等的全面开源,培育覆盖AI全栈技术且自主原生的开源创新生态。以华为开源的MindSpore为例,自主研发的开源深度学习训练和推理框架,目前已有5500多家企业基于该框架构建应用方案,合作高校360所;40多家科研院所基于该框架进行大模型、AI4S等原生AI创新工作(图3)。
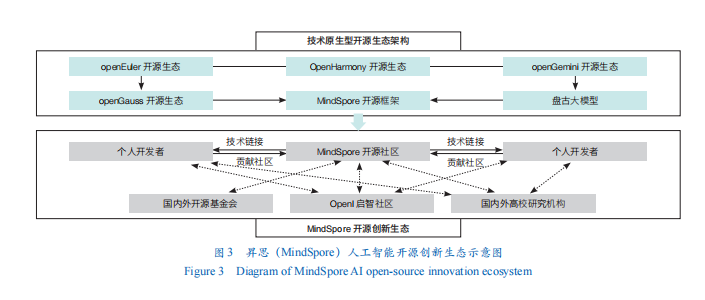
此外,华为先后加入Linux基金会、Agentic AI基金会(AAIF)和开放原子开源基金会等多个国内外有影响力的开源组织,成为多个开源组织的初创成员或顶级成员,并在开源基金会中担任董事席位,从最初的开源参与者成长为全球开源社区中不可忽视的贡献力量。
技术原生AI创新生态模式下,更强调开发者成长机制与开源生态的共生。华为等企业在开源创新生态构建过程中注重以开发者成长来反哺和增强技术实力,逐步形成了“技术原生-开发者成长”协同创新机制。通过昇腾AI创新大赛、模型开发挑战赛等方式培养社区优质开发者,在提升社区技术“原生力”的同时推动社区开发者“成长力”快速提升。
三轮驱动型开源创新生态模式
“技术+应用+资本”三轮驱动型开源创新生态是目前国内数字科技领域初创企业较为常用且有效的开源创新路径。以智谱为代表的初创企业,其开源创新生态发展路径和模式以全自研技术突破与快速的模型迭代为基础,并通过与产业界的深度合作快速响应泛在应用,加速创新成果转化落地,在创投资本的加持下实现了创新生态的持续壮大(图4)。
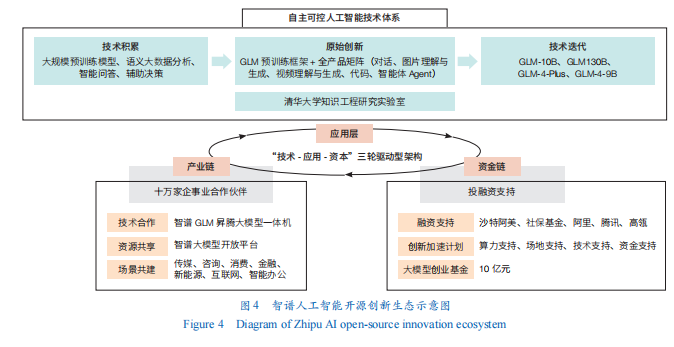
技术层面,以自主可控核心技术优势构筑国产大模型创新生态。打造从底层算法到模型框架全栈式自主可控的AI技术体系,使企业具备独立自主发展能力的同时也成为国产大模型技术创新和产业创新生态发展基础。在技术工具领域,建立智谱大模型开放平台,将大模型封装成开放平台,提供应用程序编程接口(API)给开发者和企业调用,赋能千行百业创新变革。
应用层面,以广泛的产业合作推动创新成果加速落地。智谱加强与产业界的合作,共同探索大模型技术在各领域的应用场景和商业模式。例如,在基础设施领域,智谱通过与昇腾合作,充分依托昇腾AI基础软硬件平台和完备的原生开发工具,推动大模型创新生态从“应用迁移”走向“原生开发”。
资本层面,以强大的资本流入和投资能力扩大创新生态圈。智谱积极践行“投资+孵化”双轮驱动模式,加速AI战略生态的构建,完成了对面壁智能、无问芯穹等50余家高潜力初创企业的投资与孵化,有力地促进了技术成果的转化和产业生态的繁荣。
智力聚合型开源创新生态模式
智力聚集型开源创新生态以AI领域智力人才为核心资源,通过智力人才链接国内外学术及技术创新资源,聚合智力、技术等资源构建开放生态,推动智力资源向技术优势转化,最终实现AI领域人才与技术两大关键要素的良性循环。以智源研究院等为代表的新型研发机构是智力聚合型开源创新生态的主要推动者。智源研究院聚焦原始创新和核心技术,通过科研体制、组织模式等创新,打通学术研究、创业孵化、企业研发等创新链,构筑涵盖产学研用、集学术创新与技术创新于一体的AI创新生态圈(图5)。
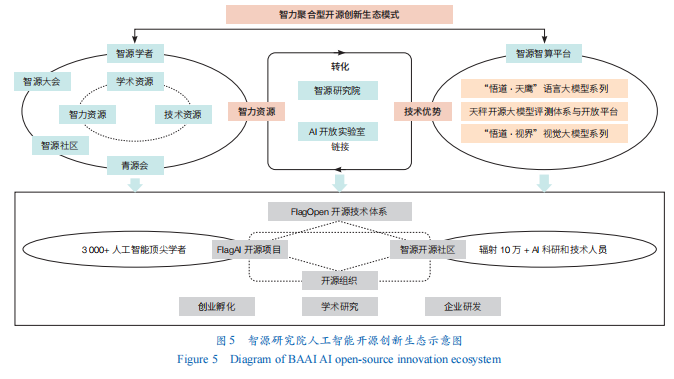
从智力资源聚合效应来看,智源研究院通过构建多层次、立体化的组织体系,成功发挥了显著的智力资源聚合效应。该体系以“智源学者”计划为核心,广泛吸纳顶尖学者;同时通过“智源大会”“青源会”“智源社区”等组织形式与平台,有效链接广泛AI人才群体,形成一个融合前沿思想与一线实践的智力生态圈。在科研团队建设方面,智源研究院秉持多元化策略,坚持AI科研人才与工程化人才并重。一方面,组建高水平前沿研究与工程化全职团队;另一方面,通过兼聘汇聚近百位“智源学者”。这种“专兼结合”的模式为AI开源创新生态提供人才与智力支撑。
从开源创新生态协作效果来看,智源研究院依托其汇聚的丰富的智力资源与开源开放平台,积极与学界、产业界建立多元协同关系,持续扩大其“AI朋友圈”。协作效果主要体现在:
攻关基础模型效率。针对大模型训练算力消耗高的行业痛点,智源研究院与中国电信人工智能研究院(TeleAI)联合研发并推出全球首个低碳单体稠密万亿语言模型Tele-FLM-1T,为算力的绿色、高效利用提供创新解决方案。
布局前沿研究方向。联合北京大学、清华大学、中国科学院等顶尖高校与科研院所,共同建设“具身智能创新平台”,重点开展数据、模型、场景验证等关键研究,致力于打造开放的具身智能创新生态。
推动底层技术共建,以FlagOS为例,目前已经成为具有较大影响力的开源项目。
产业联盟型开源创新生态模式
产业联盟型开源创新生态着眼于AI领域产业优势的培育与国家竞争力的提升。通过技术、资本、人才与产业链等多元资源的系统整合,推动技术突破转化为市场优势。相较于企业主导模式,该模式更能汇聚产学研用多方力量,实现资源高效配置与战略协同,目标不仅在于商业成功,更立足于区域及国家AI产业的整体发展,具有更宏大的战略视野。
作为国内典型代表,OpenI启智社区在鹏城实验室支持下,由新一代人工智能产业技术创新战略联盟(AITISA)推动,促进产业界、学术界、研发机构、用户、资本与服务等多类主体协同联动与资源互补,致力构建开放、协同、共建的AI技术创新生态(图6)。
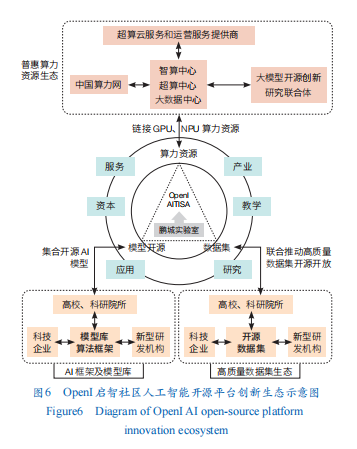
OpenI启智社区作为产业联盟型开源生态的代表,已从项目、算力、数据集和模型4个层面完成系统布局,为AI技术创新筑牢根基。
在项目共建共享方面,OpenI启智社区广泛汇聚国内外AI开源项目,覆盖模型库、算法框架、软件环境和基础设施等AI技术全链条。截至2025年11月,入驻项目达到9万个,汇聚开源资源超过15万项,具备大模型的支撑能力。
在算力共建共享方面,OpenI启智社区构建了“芯片适配—系统软件—算力网络”三级基础设施,形成覆盖硬件资源管理、开发环境支撑、跨域算力调度的全栈能力。作为中国算力网开源开放试验场,社区已接入全国超40个异构算力中心,实现算力资源的高效整合。目前,面向全社会提供290万卡・时普惠算力,惠及近18万开发者数量,覆盖近千所高校学生及200余名科研人员。
在数据集共建共享方面,OpenI启智社区联动企业、高校及科研院所打造高质量数据集生态。2024年3月,鹏城实验室联合多方共同发起具身智能开源数据集的建设倡议,依托社区开源优势,为研究者提供更加丰富多元的数据资源。
在模型共建共享方面,OpenI启智社区基于算力网部署了DeepSeek系列、鹏城·脑海、LlaMA等热门大模型在线服务。同时,联合华为昇腾、天数智芯、燧原科技等国产芯片厂商开发通用模型迁移工具链,实现1个月内完成3000余个模型的跨架构迁移。
政策建议
我国AI开源创新生态的建设,已从“多点突破”进入“系统布局”的关键时期。未来生态的繁荣,不仅依赖于各创新主体的积极参与,更取决于能否构建目标一致、权责清晰、高效协同的体系化架构。为此,基于前期研究,提出以下政策建议。
强化“战略引导政策赋能”的顶层协同。推动政策重点从“普惠性支持”转向“关键瓶颈破解”,增强政策的穿透力。聚焦“卡脖子”难题与市场失灵领域。 集中建设国家级公共算力平台,为中小企业和科研机构提供低成本算力。 发起高质量开源数据集共建计划,发挥中文与科学数据优势。 设立开源软件供应链专项,降低对外依赖。积极推进敏捷治理,成立跨部门的AI开源生态发展委员会,统筹央地政策。同时,支持开源基金会、行业协会等组织,制定开源许可证合规指南、模型安全评估与数据标注标准等具体规范,实现战略引导与基层创新的有机统一。
构筑“技术原生-开发者繁荣”的共生协同。将开发者视为生态的核心资产,从“吸引参与”升级为“赋能成长与价值回馈”。 打造极致的开发者体验。支持建设云原生一体化的AI开发平台,降低从环境配置到模型部署的全链路复杂度。重点投资于自动化评测工具链、高效调试与提示词工程工具等,极大提升开发效率。 构建可持续的激励回馈机制。超越竞赛与培训,探索建立“贡献者积分-商业资源兑换”机制,将开发者的代码贡献、文档翻译、问题解答等行为量化,并可兑换为算力、云服务或创业支持。鼓励企业设立开源贡献者奖励计划,并将其纳入技术晋升体系,让开源贡献者获得实实在在的荣誉与物质回报。
推动“科研尖兵-产业转化”的双轮协同。明确新型研发机构在连接前沿科研与产业落地中的“桥梁”角色,破解“论文导向”与“市场导向”的脱节问题。 设立“定向探索”与“自由探索”双轨机制。鼓励如智源研究院等机构,一方面围绕国家重大需求设立 “使命导向”的攻关项目,产出自主可控的大模型底座;另一方面保留一定资源用于支持高风险、探索性的“种子”项目,保持技术前瞻性。 打造“概念验证-中试孵化”一体化平台。强化其在概念验证和早期孵化中的功能。通过设立产业基金、建立联合实验室、提供产品化工程支持等方式,主动介入科研成果的早期转化,将实验室的“原型”加速转化为可被产业应用的“产品”。
构建“开源组织-价值共创”的闭环协同体系。推动开源组织从“资源链接器”升级为“价值共创平台”,构建商业闭环,丰富开源组织的多样性。 聚焦垂直行业,打造示范性解决方案。由开源组织牵头,联合成员单位在智能制造、生物医药等领域,开发行业级开源套件,形成标准,反哺底层技术。 创新开源商业模式与投融资机制。探索开源核心(Open Core)、软件即服务化开源服务等可持续模式。引导产业资本通过定向捐赠、项目孵化注入“耐心资本”。以项目汇聚、孵化、生态扩大及应用创新为核心使命,考核并激励开源组织的成效。
创新“开放融合-安全可信”的治理协同。将“治理”提升到与“创新”同等重要的战略高度,构建既能保障安全又不过度抑制创新的敏捷治理框架。 构建全方位的模型治理与评估体系。推动建立国家级的开源大模型安全评测基准与平台,对公开可用的模型进行常态化、标准化的安全性、偏见、鲁棒性评估,并向社会公布结果,为用户选择提供依据,为开发者优化提供方向。 明确权责利,防范开源法律风险。组织法律专家制定开源模型合规使用指南,明确模型开发者、分发者、使用者在不同场景下的法律责任。特别关注数据来源合规性、版权争议与模型滥用等风险,为生态的健康发展划定“安全区”。
深化“扎根国内-贡献全球”的开放协同。从“跟随融入”国际生态,转向“主动塑造”全球格局,提升我国在开源世界的话语权与影响力。 打造具有全球影响力的“中国原创”开源项目。集中资源,支持有条件的机构或企业,在AI系统软件、多模态、具身智能、科学智能等新兴前沿领域,孵化并长期运营一批根项目和根社区,吸引全球开发者参与。 主动设置国际议题,参与规则制定。鼓励我国专家、企业深度参与甚至主导Apache、Linux、LF AI & Data等国际顶级开源基金会的重要项目。围绕多语言AI公平性、跨境数据流动、AI伦理准则等全球性议题,主动提出“中国方案”,将我国的实践成果转化为国际共识。
构建“创新引领-全栈协同”的AI开源体系。面对AI向推理、智能体及产业深度融合的关键转型,亟须以开源生态为核心,推动技术全栈与产业应用协同发展,构建自主可控、开放协同的AI开源体系。 集中突破芯片、基础软件等关键环节,形成“软硬一体、自主可控”的全栈技术能力; 推动制造、科研、医疗等重点领域的开源场景创新,以真实需求牵引技术迭代与生态共建; 建立产学研开源联合体,在前沿领域布局长期性根项目,提升我国在AI开源治理与技术演进中的主导力。
(作者:隆云滔,刘海波,中国科学院科技战略咨询研究院、中国科学院大学 公共政策与管理学院;朱其罡,对外经济贸易大学 全球开源协作研究中心;任旭东,华为技术有限公司;武延军,中国科学院软件研究所。《中国科学院院刊》供稿)





