

人工智能驱动的材料科学:演进、框架、困境与破局
2026-03-31 14:57
来源:中国网·中国发展门户网




中国网/中国发展门户网讯 材料科学作为支撑现代工业体系的基石,其核心价值在于将基础科学原理转化为解决实际工程问题的物质载体。然而,长期以来,材料研发依赖经验试错与理论推演,呈现出显著的偶发性特征,这种“炒菜式”研发模式周期漫长且成本不可控,导致材料科学的前沿研究成果难以转化为满足市场需求的切实解决方案,核心应用价值无法充分体现。而人工智能(AI)凭借其在高维特征表征、海量多模态数据处理与智能优化决策等方面的独特优势,有望从根本上破解材料科学发展面临的复杂性、效率性和贯通性难题。基于此,发展人工智能驱动的材料科学(artificial intelligence-driven materials science,AIMS),已成为材料科学创新发展的关键。
从全球发展态势来看,当前中美两国在AI领域积极布局。美国特朗普政府发布《赢得竞争:美国人工智能行动计划》(Winning the race: America’s AI action plan),旨在通过放松监管框架、完善基础设施、强化出口管制等措施,抵制我国在国际AI治理中的影响力,巩固美国的全球主导地位。我国则出台了《关于深入实施“人工智能+”行动的意见》,提出“加快探索人工智能驱动的新型科研范式,加速‘从0到1’重大科学发现进程。”
从学术研究进展来看,当前围绕AIMS的研究呈现出理论深化、技术落地与场景拓展的发展态势。聚焦方法论体系的系统性搭建,将材料科学的物理规则与机器学习的拟合能力相结合;侧重具体技术手段在研发环节的落地实践,开发专用工具以解决数据稀缺、模型黑箱等问题;在具体细分场景持续释放AIMS的应用价值。现有研究对本文具有重要启示意义,然而,材料学界尚缺乏对AI驱动下的材料科学核心要素及其互动逻辑变革的深入解构,AIMS的范式体系尚待形成。
综上,在国家战略与学科发展的双重驱动下,加快构建AIMS范式体系,已成为当前材料科学领域亟待推进的重大课题。基于此,本研究在梳理材料科学研究范式演进历程的基础上,构建AI驱动材料科学要素变革的理论框架,剖析当前推进AIMS面临的困境,并提出针对性的破局路径。
材料科学研究范式的演进历程与现状
材料科学研究范式的演进脉络可划分为4个阶段,每个阶段的突破都伴随着科研效率的量级提升与认知边界的拓展。
经验试错阶段
这一阶段材料研发主要依赖经验积累和反复试错,本质上是通过大量实验寻找偶然出现的性能突破,其显著缺陷在于:试错过程缺乏理论指导,实验数据难以系统化积累,导致新材料发现具有极大的偶发性,研发周期以10年甚至100年为单位。以钢铁冶炼为例,铸铁工艺的改进依靠代代相传的经验调整炉温、配料比例,从铁器时代到现代钢铁时代跨越了数千年。爱迪生发明电灯的过程更具代表性,为寻找合适的灯丝材料,试验了上千余种材料,耗时多年才确定钨丝是合适的灯丝材料。
理论建模阶段
随着经典物理学和化学的发展,材料科学研究进入理论指导阶段。19世纪固体物理学的建立为材料性能预测提供了理论基础;20世纪,海森堡提出量子力学矩阵形式,泡利提出不相容原理,为理解材料电子结构奠定了理论框架;鲍林将量子力学应用于分子结构研究,推动了材料理论建模的发展。这一阶段的标志性成果是沃尔特拉提供位错数学模型,又经泰勒、波朗伊与奥罗万发展为位错理论,解释了金属材料强度与塑性的机制及它们之间的互斥矛盾,并指导高强度合金材料开发。理论建模使材料研发从经验试错转向定向设计,但受限于理论简化假设和计算能力,难以处理复杂多组元材料体系。例如,早期非晶合金的理论计算无法准确描述原子无序排列对性能的影响,极大地延长了研发周期,制约非晶合金高效开发。
计算模拟阶段
计算机技术的发展催生了计算材料科学。20世纪70年代密度泛函理论(DFT)的实用化,使材料电子结构计算成为可能。20世纪80年代分子动力学模拟方法的成熟,实现了材料原子尺度行为的动态模拟。Materials Project数据库的建立,推动了计算材料学的普及。计算模拟使材料研发转向“计算—实验”结合模式,但其仍面临“维度灾难”挑战。例如,在多组元合金体系中,计算复杂度随组元数呈指数级增长,五元高熵合金的理论相图计算耗时极长,严重制约复杂材料体系的探索效率。
数据密集型阶段
伴随着大数据和AI技术的发展和突破,对材料创新及其高效研制的迫切需求推动材料科学进入数据驱动的新阶段,其核心逻辑是通过整合多源数据与智能算法,构建“数据—模型—实验”的闭环研发体系,实现材料“成分—结构—工艺—性能”关联规律的高效挖掘。这一阶段伴随理念与技术的不断成熟,可进一步划分为3个阶段。
数据标准化积累与基础工具搭建阶段。针对传统研发中数据分散、实验效率低下等问题,学界与产业界聚焦数据基础能力建设。2011年,美国启动“材料基因组计划”成为这一时期重要标志,提出建立跨机构的材料数据共享框架。该阶段的核心突破在于确立“数据标准化采集—结构化存储—开放共享”的基础逻辑,为AI技术介入筑牢数据基座。
机器学习深度介入与预测模型落地阶段。随着数据规模扩大与算法精度提升,AI技术从辅助工具升级为性能预测的核心手段。2016年Nature封面文章,证实了机器学习可通过挖掘历史失败数据中的隐性规律,降低新材料筛选的试错成本。此阶段的核心特征是“数据驱动预测—实验验证”单向联动,AI开始替代部分理论计算任务。
全流程闭环与自动研制阶段。AI与自动实验系统的深度融合,推动研发模式从预测辅助迈向自主决策,形成“数据生成—模型优化—实验反馈”的完整闭环,是数据驱动材料研发的又一里程碑。国际上,美国DeepMind公司开发的GNoME模型,发现38万余个热力学稳定的晶体材料。美国劳伦斯伯克利国家实验室开发的自主实验系统(A-Lab),实现无机粉末材料无人值守合成与表征。国内方面,清华大学DeepH算法、复旦大学HamGNN算法通过深度学习预测材料哈密顿量,加速电子结构分析。中国科学技术大学系统构建了集理论计算、机器学习、自动化实验与云端基础设施于一体的智能化学实验室系统,并创新性引入大语言模型驱动的多智能体协作架构,完成从自然语言指令解析到跨设备任务调度的全流程自主操作。中国科学院东莞材料科学与技术研究所携手松山湖材料实验室,建成了具备自主知识产权的材料科学数据库、描述原子间相互作用的通用AI模型、机器人自动化实验室、Matchat材料科学垂类智能体等信息化工具体系,实现材料研发过程中“设计—筛选—合成—表征”全流程闭环。这一阶段的突破在于多尺度建模与实验自动化的深度耦合,AI从性能预测工具进化为自主研发主体,材料科学向精准设计与高效迭代的新纪元迈出了重要一步。
中美发展现状对比
当前,中美两国凭借技术积累与政策驱动居于AIMS领域第一梯队,双方在技术体系构建、数据资源整合、研发范式革新等方面形成差异化竞争优势。
美国在政策层面启动“创世纪计划”(Genesis Mission),旨在通过项目驱动和集中突破等方式整合国家科研资源,利用AI加速抢占在先进制造业、生物技术、关键材料等核心领域的科技制高点。我国工业和信息化部则出台了《新材料大数据中心总体建设方案》,北京、上海等地同步发布专项方案与行动计划,提出加快智能实验室和数据中心建设。美国在技术层面,构建了从数据生态到计算模型的完整技术体系。拥有覆盖从量子尺度到宏观尺度的全链条体系。第一性原理计算、分子动力学及宏观有限元模拟等软件成熟完善,集成化程度高,能实现不同尺度计算的有效衔接。例如,微软Azure Quantum Elements平台融合量子计算、AI与高性能计算,在成分筛选、性能预测等方面效率领先。拥有以Materials Project、OQMD、AFLOW等为代表的、规模庞大且标准统一的通用材料数据库。高通量计算基础设施成熟,实现材料计算从单点作业向协同化、集成化转变,突破分散离线模式,具备任务协同机制,能有效集成不同尺度算法程序。
中国聚焦自主数据库建设,在特色模型研发等领域持续发力。构建全国性架构体系,推动多源异构数据有效融合。例如,苏州国家实验室、北京科技大学与中国钢研科技集团有限公司共同推进国家新材料大数据中心建设,构建“1+N”架构,整合30个以上数据节点,解决材料数据碎片化问题。重点研发特色材料大模型与专用预测工具,聚焦细分应用领域打造差异化技术优势,强化材料性能预测、制备工艺优化等核心能力,形成具有自主特色的技术路径。推动高通量计算与实验平台深度协同,搭建智能化实验基础设施,建立材料研发全流程的数据采集、筛选与验证协同机制,有效提升研发效能。
综上,纵观材料科研范式的演进历程,每一次范式跃迁都伴随着科研工具的革命性突破。AI作为颠覆性的科研工具,凭借其处理高维复杂数据的能力,有望成为破解材料科学“维度灾难”的关键钥匙,从根源上突破传统范式的效率瓶颈。而这种由AI驱动的范式革命,其作用范围远不止工具层面,更是围绕科研工具、科研人员、科研对象重构材料科学的知识生产逻辑。这种系统性变革,正是新质生产力在材料科学领域孕育和发展的生动体现。
知识生产视域下AI驱动材料科学要素变革的理论框架
知识生产是对知识的创造、组织、验证与应用(图1)。材料科学研究本质上是围绕材料“成分—工艺—结构—性能”的内在关联,将对物质世界的科学理解转化为满足人类社会需求的新材料,最终实现“科学发现—技术突破—产业应用”而开展的知识生产过程。传统材料科学领域,知识生产存在局限:科研人员受困于经验积累与手工操作;科研资料依赖传统实验设备与线性分析工具;研究对象局限于孤立样本,难以建立跨尺度、多维度的构效关系网络。AIMS从底层逻辑驱动材料知识生产范式革新:智能化工具链使知识生产从经验驱动迈向数据驱动的动态循环,实现知识的高效创造与迭代;科研人员能力结构向“人机协同”重塑,跨学科团队的有组织化协作成为常态,形成多元融合的创新主体,拓宽知识创造的广度与深度;科学研究对象向跨尺度耦合系统(从原子到器件)和全生命周期(从实验室合成到工程应用)拓展,同时精准对接实际需求,提升知识的应用价值与转化效率。
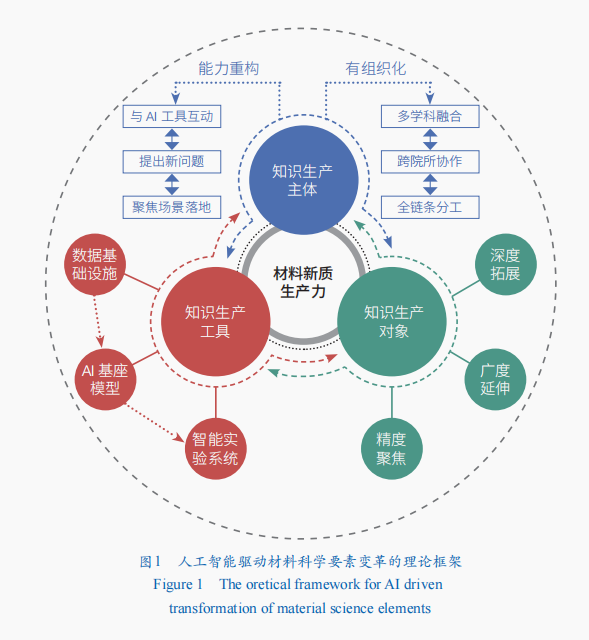
智能化工具链变革知识生产逻辑
科研工具的智能化升级是知识生产范式转型的物质基础。AIMS凭借“数据—模型—实验”闭环迭代的智能化工具链,重构材料知识生产的核心逻辑,实现知识从生成、验证到优化的全链条革新。
材料数据基础设施是知识生产的“核心底座”。通过整合高通量计算、自动化实验、文献知识数据与经典书籍语料,建立跨尺度映射规则与质量校验机制破解“数据孤岛”问题,形成标准化、动态更新的材料知识原料库。这一底座既为AI模型提供初始训练数据,又接收实验反馈的新数据持续丰富数据维度,实现知识生产原料的动态供给。
材料AI基座模型是知识生产的“智能中枢”。融合科学机理与深度学习技术,构建具备跨空间和时间尺度预测能力的通用模型体系,围绕“数据学习—规律挖掘—决策输出—反馈优化”全链条,从高维数据中提取材料“成分—工艺—结构—性能”的关联规律。该模型既为实验系统提供精准指令,又通过误差反馈持续优化参数,确保知识输出与实际需求的动态适配,解决传统材料创制和知识生产中理论与实践脱节的痛点。
智能实验系统是知识生产的“验证与反哺终端”。通过打造多智能体协同的自动化平台,集成机器人制备、智能表征与性能测试模块,将模型决策转化为实物实验,实现对新知识的实践验证。实验结果一方面验证模型预测的有效性;另一方面将新数据实时反哺至数据基础设施,为知识生产注入新变量,形成“数据喂养模型—模型指导实验—实验丰富数据”的知识生产闭环,推动研发链条迭代加速。
以AI赋能非晶合金研制为例,通过整合非晶合金历史实验数据、高通量计算结果、多尺度模拟参数及文献、书籍知识,构建涵盖多元组元成分、热力学特征、拓扑参数与力学、磁学、电学性能的标准化数据库,为知识生产、新体系研制提供动态更新的原料支撑;依托支持向量机、随机森林等算法构建AI基座模型,实现对合金玻璃形成能力及关键性能的精准预测,同时以混合建模嵌入热力学—动力学机理,揭示“成分—结构—性能”的关联规律,完成多目标性能协同优化与逆向设计决策;在此基础上,借助高通量熔炼、自动化表征与性能测试的智能实验系统,将模型输出的候选成分快速转化为实物试样,实验数据实时反哺数据库并驱动模型通过主动学习迭代优化,形成“数据喂养模型—模型指导实验—实验丰富数据”的闭环链条,实现非晶合金从知识生成到应用落地的全链条加速。
科研人员能力重构与组织模式优化提升知识生产效能
科研工作者作为知识生产中最具能动性的核心变量,其知识储备、创新思维与协作能力直接决定知识生产的深度与价值转化质量。AIMS范式下知识生产主体从人类独立主导向人机协同共创演变,通过重构科研人员能力体系与优化科研团队的科研组织模式,实现人类创造性思维与机器高效算力的深度融合,释放知识生产、材料创制的协同效能。
知识生产主体能力的范式迁移是核心支撑。传统材料科研人员以专业知识和实验技能为核心素养,注重通过经验积累和人工操作完成实验;而AIMS范式下,材料AI模型与智能实验系统替代了成分筛选、样品制备和表征、数据统计分析等重复性、机械性工作,转而要求科研人员掌握、智能实验操作等人机协作技能,重构其能力结构。更重要的是,科研人员可以从繁琐枯燥的实验流程中解放,把核心价值转向提出关键科学问题、设计研究框架和深度解读模型结果,从而更加聚焦新材料设计思路创新、应用场景落地策略制定等高价值知识生产环节,形成人机各擅其长的协同格局。
科研团队的有组织化是知识生产效率的保障。传统材料科研方式是“小作坊”的首席研究员(PI)模式,一个个团队是一个个“科研孤岛”。面对材料知识生产向复杂化、极端化、深层次拓展的发展趋势,仅依靠个别科研团队“单打独斗”已难以催生重大科学突破,尤其难以解决AIMS在组织层面的复杂工程性问题。因而,需要组建跨领域、跨学科、跨研究方向的科研队伍,凝聚集体力量,通过一种分工明确而协作紧密的科研组织模式,既保障个体科研团队(人员)的专业化效率,又以知识互补与资源共享激活创新动能。
具体来看:组建跨学科科研团队以整合材料科学、AI、数据科学、工程技术等多学科知识,打破单一学科认知边界,形成多维度知识生产网络。依托各类科研院所的优势领域开展专业化分工,基于各研究机构核心职能定位形成层级化协作网络。例如,聚焦特定材料体系研发的机构深耕细分领域数据积累,构建包含合成配方、物理性质与工艺参数的专业化子数据库;侧重基础理论研究的机构以高通量计算产出原子级、介观尺度基础数据,主导跨源数据的标准化整合与同源性校验;具备实验技术优势的机构依托自动化实验平台开展材料合成与性能测试,提供实验端数据支撑。各主体以标准化数据互访机制为纽带,依托大科学装置实现理论数据与实验数据的闭环交叉验证,推动材料数据资源全链条高效流转,形成协作闭环。处在创新链不同环节的科研人员围绕“基础研究—技术开发—工程应用”开展全链条分工,材料科学家深耕构效机理和实验验证、AI工程师专注模型开发与优化、工艺专家聚焦量产工艺参数调试与稳定性控制,实现对知识生产的全流程覆盖,产生“1+1>2”的协同效应。
目前,国内外正积极探索与AIMS适配的科研组织模式革新。例如,中国科学技术大学精准智能化学全国重点实验室探索工程化管理提升科研效能,构建“任务拆解—节点管控—动态追踪”的精细化管理体系,通过将科研目标分解为具体任务,明确责任人、时间节点及交付标准,实现全流程可视化管控。强化跨领域团队接口化管理,推动理论计算、实验合成、AI算法等环节通过标准化平台对接,确保“理论推导—实验验证—数据反馈”高效运转,以有组织科研破解传统研究碎片化问题。
研究对象拓展丰富知识生产维度
科研对象的边界决定了知识生产的范围与价值。AIMS范式下的科研对象从孤立样本向系统关联、从实验室静态向全生命周期动态拓展,实现知识生产深度、广度和精度的跃升,将极大提升新材料等科技成果的应用转化和产业化效率。
知识生产深度向多维度耦合系统突破。传统材料研究难以触及多因素非线性耦合的本质规律,AIMS通过高维参数空间建模,将原子尺度的键能、电子态密度,介观尺度的晶粒分布、缺陷演化,宏观尺度的工艺参数、服役环境等多维度变量纳入研究对象范畴,构建跨尺度构效关系网络。这一转变使科研对象从“孤立的材料样本”升级为“动态关联的系统参数集合”,为揭示材料性能本质规律提供全新知识视角,解决传统知识生产中局部认知局限等问题。
知识生产广度向全生命周期场景延伸。传统研究以实验室标准样品为对象,侧重短时间、单一工况测试,难以覆盖材料从合成到退役的全生命周期演化。AIMS通过整合自动化实验、工业生产、服役监测多源数据,构建材料数字孪生体,将研究对象拓展至真实应用场景的动态性能变化。这一拓展使科研对象从静态的实验室样本转变为动态的全生命周期性能演化过程,大幅提升知识生产与实际应用需求的贴合度,便于研究成果的放大、量产和应用。
知识生产精准度向战略需求导向聚焦。传统材料研发常陷入“广撒网”式低效探索,而AIMS通过挖掘国家战略领域需求痛点,将科研对象精准锁定于“卡脖子”关键材料体系。这种“需求牵引—智能设计—应用验证”的知识生产链条显著提升科研资源配置效率,实现知识生产价值与国家战略需求的深度绑定。
以软磁合金智能创制为例,传统研究多针对单一成分或工艺参数与磁导率、损耗等性能的简单对应关系,难以兼顾高频工况下饱和磁感应强度、矫顽力与热稳定性的协同优化。AIMS通过构建跨尺度模型,将原子层面的磁矩排列、介观尺度的晶界分布与宏观的退火工艺、服役温度等多维度参数纳入研究体系,形成“微观结构—工艺调控—服役性能”的动态关联网络。同时,整合材料合成阶段的熔炼数据、加工过程的轧制参数及实际应用中的损耗监测数据,构建软磁合金数字孪生体,实现从实验室制备到电力电子器件长期服役的全生命周期性能追踪。这种研究对象的拓展,不仅揭示了软磁合金在高频强磁场下的性能退化机制,更精准锁定了满足第3代半导体器件需求的低损耗、高稳定性软磁材料研发方向,使知识生产直接对接新能源、6G技术等战略领域的核心需求,并且能够高效、低成本实现产业化。
从动态来看,AI驱动下的材料科学并非单一要素变革,也是科研人员、科研工具和科研对象的动态协同过程,这一过程中存在2条逻辑主线:科研人员运用AI工具提升材料知识发现效率,加速材料价值实现。从材料科学自身发展的规律来看,其持续“向极宏观拓展、向极微观深入、向极端条件迈进、向极综合交叉发力”,需要不断突破知识边界,从而倒逼科研工具升级,并要求进行有效的分工协作。同时,智能化的科研工具和新范式下的知识生产也对科研人员的素质能力提出了新要求。综上,AI与材料科学核心要素深度融合,在科研主体、科研工具与科研对象的矛盾运动中催生了AIMS研究新范式,释放出全新的知识生产效能,从而驱动材料新质生产力形成。
AIMS面临的困难瓶颈
AIMS虽具备广阔前景,但仍面临多尺度建模、多模态数据融合、模型泛化与可信度等难题,亟待相关科研单位统筹突破以进一步释放其巨大潜力。
多尺度知识建模存在割裂
材料“工艺—结构—性能”的跨尺度关联存在系统性断层,难以形成完整知识链条。
跨尺度物理机制耦合困难。材料性能由原子/电子层面的微观结构、介观组织特征到宏观服役行为的多尺度演化共同决定,但现有算法难以精准刻画不同空间和时间尺度间的动态关联。例如,非晶合金的玻璃形成能力(GFA)与原子堆积密度、短程有序结构相关,而宏观GFA预测需耦合热力学驱动力与动力学冷却速率,现有模型难以整合原子扩散冻结(纳米空间尺度、飞秒时间尺度)与宏观铸件尺寸(厘米空间尺度、年的时间尺度)的关联规律。
跨尺度数据对齐与融合不足。不同尺度研究的时间步长、空间分辨率差异巨大,数据难以直接关联。例如,先进钢铁研发中,微观位错演化数据与宏观疲劳寿命测试数据缺乏统一表征框架,难以通过微观组织参数精准预测构件服役寿命;磁性材料的自旋结构(原子级)与高频磁性能(宏观级)的跨尺度映射模型缺失,制约全频段磁性能优化。
多模态数据融合机制缺失
多源异构数据的标准化整合与协同利用存在障碍,形成“数据孤岛”。
数据格式与标准不统一。材料研发涉及的文献文本数据、实验测试数据、计算模拟数据、微观图像数据等多模态数据缺乏统一存储格式与表达规范,兼容性较差。例如,非晶合金的混合焓ΔHmix、原子半径差δ等热力学参数与宏观GFA测试数据因测试标准不一,难以直接整合建模;蛋白质设计中,PDB数据库的结构数据与文献中的功能注释数据格式异构,难以支撑“序列—结构—功能”全链条建模。
跨尺度数据关联断裂。从电子结构计算数据到器件性能测试数据的跨数量级数据缺乏统一表征框架,难以建立有效关联。例如,锂电材料的正极材料晶体缺陷(原子级)与电池循环寿命(宏观级)数据缺乏映射规则,难以通过微观结构参数优化电池长循环性能;超导材料的临界温度计算数据与薄膜制备工艺参数(如沉积速率、温度)难以形成关联体系,制约高温超导带材性能提升。
数据质量与完整性不足。主要包括多模态数据存在噪声高、标注不一致等问题,且关键场景数据缺失。例如,在天然细胞外基质(ECM)仿生材料的研发中,人源三维微环境的“结构—功能”数据稀缺,现有数据多来自二维细胞培养或动物模型,与临床实际场景偏差大;半导体材料的极端条件性能数据积累不足,导致AI模型在复杂工况下的预测可靠性有限。
模型泛化能力受限
材料AI模型在新研究体系、复杂、极端服役场景及跨材料体系中的预测准确性与适应性不足,对实际研发需求的支撑能力较弱。
在新型材料体系中预测精度较低。面对未充分覆盖的新材料体系,模型因训练数据中缺乏同类样本,易出现过拟合或预测偏差。例如,因非晶合金领域数据稀缺,且失败样本占比极低,AI模型在高熵非晶等新体系中预测玻璃形成能力(GFA)时,常因未学习到复杂多元组元的共性规律而失效。
在复杂工况下预测可靠性不足。针对极端服役环境,因缺乏足够的工况数据训练,模型难以准确捕捉材料性能演化规律。例如,先进钢铁的研发中,极低温下的疲劳性能数据积累不足,AI难以精准预测国际热核聚变实验堆计划(ITER)超导磁体用钢在极端电磁载荷下的安全服役寿命;锂电材料的针刺、过充等安全测试数据稀缺,热失控风险预测模型在实际复杂工况中易出现误判,难以满足动力电池安全性要求。
跨材料体系迁移时性能衰减。AI模型在已知材料体系中表现稳定,但迁移至特性差异较大的新体系时,预测能力则下降。例如,基于传统软磁材料训练的AI模型,因未学习到二维磁性材料的自旋耦合机制,而难以有效预测其磁各向异性;高分子材料模型从通用塑料迁移至聚酰亚胺等特种工程塑料材料时,因成分复杂度提升,力学性能与耐温性预测准确率降低。
模型可解释性与可信度不足
“黑箱”特性导致模型预测逻辑难以追溯,制约AIMS在关键领域的应用渗透。
物理约束嵌入不足。部分模型因缺乏对物理规律的显式嵌入,易导致预测结果违背基本科学原理。例如,在氢能催化剂设计中,AI模型尚未充分嵌入表面反应动力学机理,难以准确预测不同温度、压力下的催化活性衰减规律。
决策路径不可追溯。现有模型因无法充分揭示“成分—工艺—结构—性能”的内在因果关系,导致难以为实验优化提供可操作的机理指导。例如,高分子材料生成模型推荐的共聚单体组合,难以说明单体比例与耐温性的定量关系;超导材料工艺优化模型给出的沉积温度参数,难以解释其与临界电流密度的关联规律。
评估标准缺失。当前对模型可解释性尚缺乏统一完善的量化评估指标,缺乏对物理一致性、机理吻合度、结果可重复性等核心维度的明确量化标准。例如,航空航天用材料的AI设计方案因难以解释性能优化逻辑,难以通过工程化验证;半导体材料缺陷预测模型的“黑箱”输出,难以满足芯片制造对可靠性的严苛要求,制约产业端应用。
推进我国AIMS发展的建议
AIMS作为材料科学范式变革的核心驱动力量,其发展水平直接关系我国在新材料领域的自主创新能力与全球竞争话语权。面对现存挑战,需从数据底座筑牢、核心技术攻坚、创新生态优化多维度协同发力。为此,本文提出如下建议。
围绕标准化、规模化与安全共享,夯实数据底座
材料数据是AIMS系统的关键支撑要素,其标准化、规模化与安全共享水平很大程度上决定了智能体的能力边界,《赢得竞争:美国人工智能行动计划》便提出创建全球最大、质量最高的“AI-ready”科学数据集。针对当前我国材料数据生态存在标准化缺失、供给不足、流通梗阻等痛点,需从国家层面统筹推进,加速建设国家级、高质量的材料科学数据库,提升高质量数据供给能力,将数据资源真正转化为国家战略资产,以夯实材料智能研发数据底座。
构建全生命周期数据治理标准体系。制定覆盖采集、存储、标注、验证全流程的国家级数据标准,统一多模态数据格式与跨尺度映射规则,同步完善质量评估与伦理审查规范,破除数据碎片化与语义歧义瓶颈,确保数据可用、可信、可复用。
打造规模化数据供给与协同平台。整合高校、科研院所及大科学装置产生的高通量同源数据,构建覆盖“原子—介观—宏观”全尺度的标准化数据集。强化极端工况下的稀缺数据采集能力,通过大科学装置的高通量特性与自动化实验的标准化流程,确保数据同源性与可复现性,支撑材料AI模型跨场景训练与泛化能力提升。
建立安全可控的数据流通与价值释放机制。搭建国家材料可信数据空间,运用隐私计算、区块链等技术实现数据可用不可见。探索数据资产化评估与市场化交易机制,破除数据跨主体流通壁垒。积极参与国际材料数据标准制定,推动我国材料数据平台与国际主流数据库互通,提升全球材料数据治理话语权,构建开放共享的数据生态。
强化重点领域数据专项布局。借鉴生命基因组测序的思路,针对高端制造、新能源、生物医用等战略领域的关键材料,启动系统性数据采集专项,构建细分领域专用数据集,支撑材料专用AI模型的训练与迭代,加速从基础研究到产业应用的数据价值转化。
聚焦跨尺度建模与智能算法突破,攻关核心技术
核心技术的突破与应用是实现AIMS真正落地的关键支撑。面对当前跨尺度机理难刻画、多源数据难融合、新体系适配难落地、全链条优化难实现等瓶颈,需围绕物理机理与算法的深度耦合、数据标准与关联规则的体系构建、小样本学习策略的创新应用,以及数字孪生技术的全周期赋能,为材料智能研发筑牢技术根基。
突破跨尺度融合建模技术。将热力学定律、扩散理论等物理机理作为先验约束嵌入算法,开发融合第一性原理、分子动力学与宏观力学的混合建模框架,精准刻画“原子/电子—介观组织—宏观性能”的动态关联,破解如非晶合金玻璃形成能力与原子堆积规律、磁性材料自旋结构与高频性能等跨尺度映射难题。
发展多模态数据融合技术。制定覆盖实验数据、计算数据、文献文本、微观图像的统一表征标准,开发跨模态特征对齐算法,建立多源数据关联规则,解决诸如非晶合金热力学参数与宏观性能数据、蛋白质结构与功能注释数据等融合障碍。
创新小样本与迁移学习算法。针对新体系数据稀缺问题,构建基于已知材料体系的预训练模型,通过参数微调实现诸如对高熵非晶、二维磁性材料等新材料体系的快速适配;开发主动学习策略,优先选择信息量大的样本开展实验,提升模型在复杂工况下的泛化能力。
发展数据驱动的数字孪生技术。建立材料全生命周期虚拟模型,通过实时数据交互实现虚拟与实体实验的双向优化,模拟极端工况下的性能演化规律,降低实体实验成本,支撑从微观结构设计到宏观服役性能预测的全链条加速。
以学科建设、共识凝聚与评价体系建立为抓手,完善生态保障
针对当前AIMS面临的复合型人才短缺、跨主体协作壁垒、模型评估标准缺失等生态短板,需从学科融合、共识凝聚、标准构建等维度统筹发力,为AIMS范式真正形成提供落地生根的沃土。
优化交叉学科布局,夯实人才支撑。加快建设“AI+材料”学科体系,系统培养既懂材料机理又掌握AI工具的复合型人才。整合材料、计算机、自动化等学科资源,围绕四大板块开展材料AI课程体系建设:基础核心模块筑牢跨学科知识根基;AI与大数据模块培养数据处理与算法应用能力;交叉融合模块实现理论与方法跨界融合;实践应用模块强化场景化操作能力。同时,建立校企协同育人平台,引入企业真实研发项目,打造集教学、科研、实践于一体的产教研基地,强化多模块知识的场景化应用。
构建科学共同体,提升协同效能。以形成AIMS统一研发范式为核心,搭建跨领域、多层次的学术协作网络。通过定期举办全球材料智能化研发峰会、设立跨机构联合攻关项目,推动科研单位、高校、企业在材料数据库、跨尺度建模框架、实验自动化协议等AI驱动材料研发的方法论和技术路径上形成共识,消除不同研究单元间的技术壁垒与认知差异。积极主导或参与国际材料智能研发规则制定,推动我国技术体系与国际标准对接,同时引入全球前沿经验反哺国内共识完善,强化科学共同体对AIMS范式的集体认同,提升全球创新协同效能。
建立科学规范的材料智能体评价体系,保障AIMS安全可控发展。构建覆盖模型设计、训练、测试、应用全生命周期的国家标准,明确数据格式、测试方法与评估指标,形成标准化评估链条。建立涵盖科学合理性、工程适用性、伦理合规性的多维指标框架,配套行业级基准测试套件实现系统化评估。整合多方评估资源,引入企业参与场景设计,建立结果共享反馈机制,同时参与国际标准制定与互认,提升全球评估话语权。
(作者:周杨理理、赵紫威,中国科学院东莞材料科学与技术研究所松山湖材料实验室;汪卫华,中国科学院东莞材料科学与技术研究所;《中国科学院院刊》供稿)





