

细胞工厂设计数字化赋能绿色生物制造
2025-02-14 09:06
来源:中国网·中国发展门户网




中国网/中国发展门户网讯 绿色制造是综合考虑环境影响和资源效益的现代化制造模式,而绿色生物制造作为绿色制造重要的方式之一,具有得天独厚的优势。绿色生物制造以生物细胞及其酶的反应过程为核心,以CO2、木质纤维素、农作物废弃物、其他可再生生物基碳源等为原料,生产燃料、药物分子、材料、大宗化学品和食品等低碳、可持续发展产品,实现原料获取、过程制造的绿色化和低碳化。绿色生物制造可以实现资源的高效利用和环境的可持续发展,是国家提出大力发展的新质生产力的重要组成部分。绿色生物制造以高科技、高性能、高质量等为特征,完美契合新质生产力,是符合新发展理念的先进生产力质态。
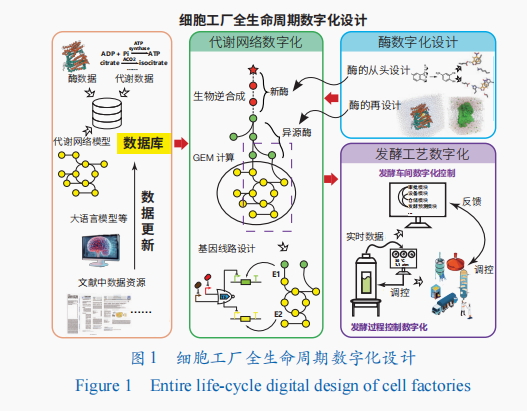
高性能细胞工厂作为绿色生物制造的核心,是工业发酵过程的主体。为响应快速发展新质生产力的号召,细胞工厂需要快速更新迭代以适应不同的生产环境,以及追求更高的生产性能,这对细胞工厂的精准设计、快速迭代、发酵过程控制等提出了极高的要求。而随着计算领域的发展,“数字孪生”(digital twin)实现了对化工过程优化与控制、新产品开发与测试等的数字化,人工智能更拓展并提高了数字孪生的应用范围和效果。基于类似的想法,对细胞内复杂的生物过程进行数字化模型构建,构建多种数据库,并利用机器学习等手段对酶、细胞工厂代谢网络、发酵工艺等进行数字化,形成细胞工厂全生命周期数字化设计方法(图1)。利用这些方法,可以快速、高效获得高性能细胞工厂,赋能绿色生物制造。
细胞工厂数字化基础:代谢数据库、酶数据库
数据是数字化的基础。在细胞工厂中,由酶催化的代谢反应是实现细胞生长、产物合成的关键。代谢数据库包含代谢化合物、生化反应、催化生化反应的酶、代谢反应组合形成的代谢途径等信息,是代谢网络数字化的基础。
代谢数据库、酶数据库的发展现状
近年来,随着互联网时代的来临,酶、代谢数据的共享为研究人员带来了极大的便利(表1)。KEGG、MetaCyc(BioCyc数据库子数据库)等常用的综合代谢数据库在分子水平建立了对细胞代谢的系统认知,Brenda、PDB、Uniprot等酶反应数据库则聚焦代谢反应酶的结构与功能。代谢数据库和酶数据库的结合,将由代谢途径组成的代谢网络,与酶结构功能、催化活性、细胞定位等的酶催化数据相结合,形成对细胞工厂代谢的系统性表征。同时,随着研究的深入,HMDB(人类代谢组数据库)、SGD(酵母基因组数据库)、GMD(植物代谢组数据库)等物种专有代谢数据库、基因数据库,在特定的应用环境中也发挥了重要作用。
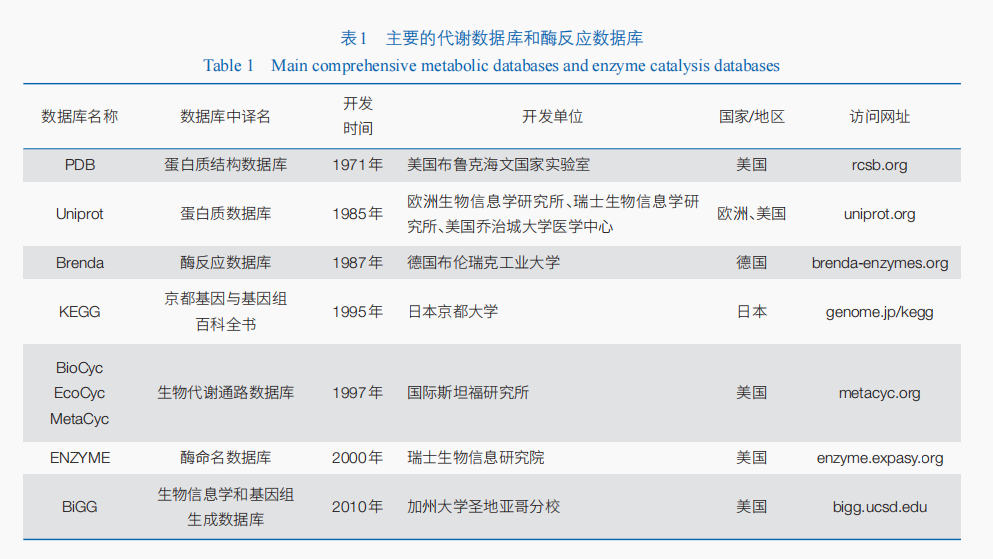
我国在发展和建设自主知识产权的高质量代谢、酶数据库方面发展较晚,导致我国在绿色生物制造产业发展安全及在国际上的核心竞争力存在一定程度的隐患。为此,近年来国家和研究人员开始重视生物科学数据的标准化及安全管理,颁布了《中华人民共和国生物安全法》,同时依托《中华人民共和国数据安全法》等法律法规,推进生物科学数据的标准化数据库构建与规范化管理。
基于大语言模型的数据库更新方法
随着合成生物技术的发展,细胞中新酶、代谢反应的更新速度呈指数级增长,传统数据库更新及维护需要人工对信息进行整理,存在一定滞后性。随着计算机技术的发展,通过机器学习挖掘文献中文本提取代谢相关信息成为可能,而近几年GPT-4、Bard等大语言模型(LLM)在生物医药领域的发展与应用,更是提高了生物代谢信息提取的速度与准确性。而在部分文献中,代谢途径信息以图片格式展示,为提取这部分不在文本中的代谢数据信息,在最新的报道中,研究人员使用包括Faster R-CNN和PaddleOCR的机器学习模型对文献中包含代谢途径的图片进行识别,实现了高通量、全面地从文献中提取代谢反应信息。随着机器读文献中信息获取能力和准确性的提升,代谢数据库、酶数据库的数据更新将更具时效性。
细胞工厂酶的数字化设计
酶是细胞中代谢反应的核心,酶的功能、活性、选择性直接影响细胞工厂的产物合成能力。酶的数字化设计为细胞工厂中代谢反应提供了高效的催化剂。通过数字化方法,预测蛋白质结构与功能,并进行酶的改造设计,可将酶的催化活性提高数百甚至上千倍。例如,通过理论计算-实验验证,ω-转胺酶的kcat/Km值提高了1 660倍。
蛋白质结构预测
蛋白质结构是其功能的基础,数字化酶的设计依赖于蛋白质结构的精准预测。根据不同的预测思路,研究人员开发了多种蛋白质结构预测软件,包括基于同源建模的SWISS-MODEL、基于无模板方法的Rosetta等。而Google DeepMind团队基于深度学习算法开发的Alphafold在精准预测蛋白质结构的基础上,更提高了蛋白质、核酸、小分子、离子间互作结构的预测准确性,将生物大分子结构预测推上了新高度。
细胞工厂酶的改造——酶的再设计
酶的再设计根据已有酶的结构功能,对催化活性中心或其他关键位点氨基酸进行突变,并通过量子力学模拟(QM)、分子动力学模拟(MD)、粗粒化(CG)模拟、分子对接等计算生物化学手段进行分析,并指导湿实验验证,实现以催化活性提高或耐受能力提高等为目标的快速酶设计。
细胞工厂酶的创新——酶的从头设计
蛋白质结构决定功能,而理论上蛋白质的氨基酸序列决定蛋白质结构,已知功能酶的量级远远小于由随机氨基酸序列组成的“蛋白质空间”。相比于酶的再设计,酶的从头设计旨在结合已有酶骨架结构及功能特点,拓展已知功能酶在蛋白质空间中的范围,实现新功能酶的设计,探索浩瀚未知的蛋白质空间。限于酶从头设计的难度,现阶段高性能软件及成功案例相对较少,包括ORBIT、DESIGNER、Rosetta、CCBuilder、PRODA等在内的多种软件能够实现酶的从头设计。其中Rosetta针对自然界中没有酶可以催化的化学反应,如Kemp消除反应、逆醛缩反应等,进行酶的从头设计,创造了可以催化这些反应的人工设计酶,拓展了酶可催化反应的种类,Rosetta的开发者David Baker也因在计算蛋白领域的贡献获得2024年诺贝尔化学奖。
细胞工厂代谢网络数字化设计
酶的数字化实现了酶催化代谢反应的优化及新功能酶的设计,拓展了以酶催化反应为核心的细胞工厂的功能。在细胞工厂的代谢层面,细胞内源的酶促反应会组成复杂的代谢网络,而通过合成生物学添加的外源路径更增加了细胞工厂设计的难度。为实现目标产物的高效合成,在细胞工厂中,需要对复杂代谢网络中物质流、能量流、异源合成路径等进行组织优化,这通常需要耗费大量的物力和时间成本。基因组尺度代谢网络模型(GEM)、生物逆合成途径预测、基因线路数字化设计等数字化方法可以指导细胞工厂的设计,减少试错成本(图2)。
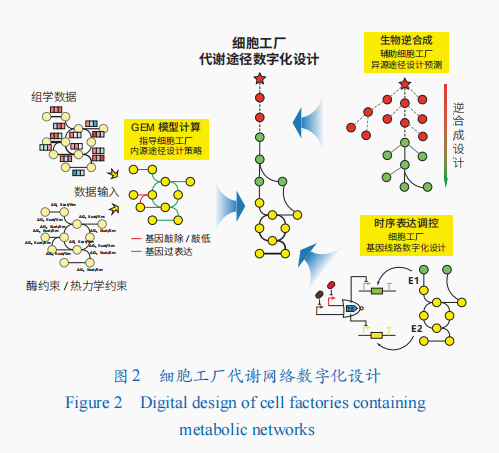
基因组尺度代谢网络模型(GEM)指导细胞工厂代谢网络数字化设计
GEM将代谢网络数字化,以描述生物体整个代谢途径中基因—蛋白质—代谢反应的关系特征,是通过数学模型模拟细胞内代谢反应的系统生物学研究方法。自研究人员首次在流感嗜血杆菌中完成了GEM的构建与应用,在接下来的20余年中,为提高GEM计算的准确性,在以代谢流矩阵为核心的代谢流平衡分析(FBA)基本算法的基础上,添加了酶约束、热力学约束及多约束等不同层次的附加约束,并结合转录组学、代谢组学等实验数据,实现了多种生物高质量GEM的构建与应用]。而随着获取实验数据成本降低、数据更新速度加快,GEM也在不断地更新重构,以适应不同的应用环境。
GEM的模型构建方法主要包括:手动构建、自动构建和半自动构建。2010年COBRA ToolBox工具箱的开发实现了GEM手动构建的数字化,但手动构建需要耗费大量的时间。自动与半自动工具加快了GEM模型的构建,自动构建GEM,如Model SEED等工具箱可以快速大批量生成多个物种的GEM,但数据质量很大程度影响自动构建的GEM模型的精准度。而半自动构建GEM的工具既可以快速收集数据,又可以进行手动数据校正,保证了快速构建的模型的精准性,成为现阶段GEM构建与重构的主要方法。现阶段半自动构建模型的方法逐渐成熟并趋于标准化,已有多种工具箱被开发使用:RAVEN工具可以重构和分析GEM,并将结果进行可视化;Merlin集成了序列匹配与亚细胞定位功能,使得其使用极为方便;GECKO工具通过动力学和分子生物学数据向GEM中添加酶制约因素,从而提高GEM预测能力。
利用构建的模型,通过FBA算法计算细胞内代谢流量,预测细胞以最大化生长或生产产物为目标的代谢通量,进而为理解细胞内的代谢流量变化提供帮助;而MOMA、FSEOF及OptKnock等算法则以提高生长与生产为目标,预测细胞代谢通量分布,并提供基因表达强度优化策略,为细胞工厂实验设计提供指导。
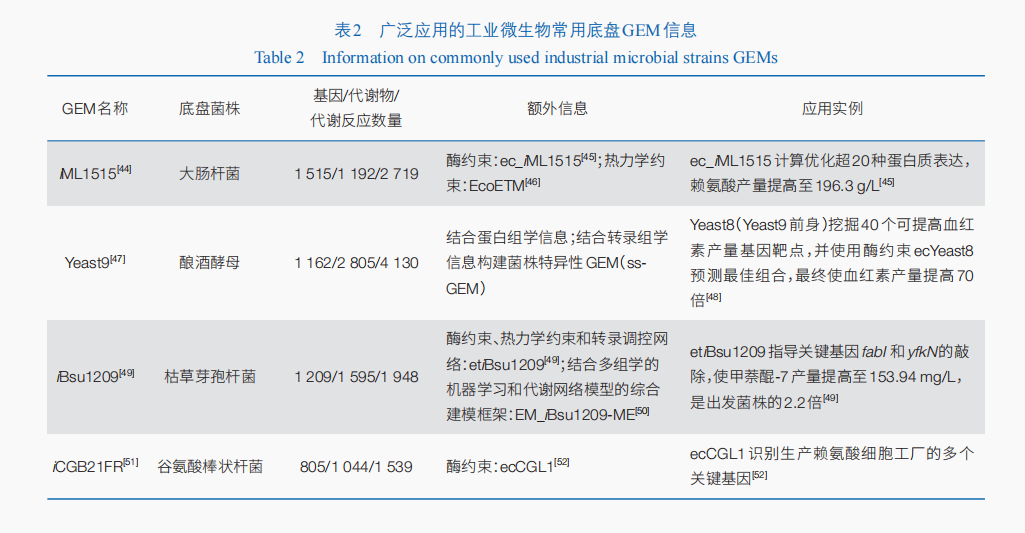
随着数据更新速度的加快及模型构建技术的更新,研究人员实现了对多种工业微生物GEM的重构与迭,并应用这些GEM实现了工业细胞工厂代谢网络的数字化设计(表2)。
生物逆合成工具辅助细胞工厂异源途径设计
在进行全新化合物或从未在细胞工厂中完成从头合成的化合物的细胞工厂构建过程中,需要大量的时间精力进行未知途径的解析及途径设计,且这个过程强烈依赖专家知识。数字细胞工厂通过生物逆合成策略,结合数据库中数据信息,针对目标分子,通过反应规则、机器学习等方法,利用酶的杂泛性拓展酶催化反应空间,将目标分子复杂结构逆向解析,以细胞工厂内源代谢物为逆合成目标终点,实现细胞工厂外源代谢途径的逆合成设计。逆合成设计结合上述章节中介绍的酶的从头设计、再设计,及细胞工厂代谢网络数字化设计,形成完整的目标分子细胞工厂代谢途径设计。
生物逆合成在目标分子异源合成途径设计中,根据原理和实现难易程度,可以分为2类:基于已知酶、代谢反应的知识库搜索方法;基于反应规则提取或机器学习,预测未知的、新的酶促反应的方法。这2种方法可以进行组合,实现更贴合实验设计思路的逆合成路径设计。
基于知识库搜索的途径设计方法由于无法超越数据库中数据,受限于已知酶促反应的数据规模。通过蒙特卡洛树搜索(MCTS)、无环路径搜索等算法,构建了DESHARKY、Metabolic tinker等软件,实现了基于已知酶促反应的逆合成途径设计,成功发现碳利用率、能量利用率更高的新途径,并应用在细胞工厂构建中。
在新酶促代谢反应预测方面,按拓展新酶促反应的方法可分为:基于反应规则的逆合成设计方法、无模板逆合成设计方法、半模板逆合成设计方法。
基于反应规则的逆合成设计通过原子—原子映射等方法从已知数据库中提取反应规则,并使用标准化方法形成反应规则数据库。例如,RetroRules、Ni等从MetaCyc数据库抽提并精简的包含1 224条反应规则的规则数据库;RetroBioCat软件使用的包含99条的极简反应规则数据库等;通过MCTS等算法构建逆合成途径设计软件,基于RetroRules的RetroPath2.0、RetroPath RL、RetroBioCat等。
无模板逆合成设计方法使用反应数据库来训练机器学习模型,将“反应物—产物信息对”视为翻译过程,使用自然语言处理(NLP)进行模型构建,实现逆合成反应途径的拓展,基于此方法已开发了BioNavi-NP、基于酶EC号的预测模型等算法或软件。
基于反应规则的逆合成设计结果中,通过反应数据库—反应规则数据库的映射关系可以提供预测途径的酶参考信息,可以基于已有信息进行酶的数字化设计,但设计的途径受限于反应规则数据库。而无模板逆合成设计方法通过机器学习,极大拓展了酶促反应空间,但由于酶促反应数据量对于机器学习而言仍然较小,其准确性仍有待提高。而基于深度学习开发的半模板逆合成设计软件,如RetroPrime、G2Retro则通过分子图捕捉分子结构特征,解决了无模板方法中已有SMILES式为唯一输入使得模型无法理解分子结构信息的问题。半模板方法通过预测反应中心提高了模型的可解释性,并通过深度学习保证了逆合成预测的拓展能力和多样性。
基因线路数字化设计调控基因时序表达
为了满足细胞工厂基因表达的时序调控、不同代谢模块之间的代谢通量调节等需求,需要进行基因的逻辑、时序、定量表达调控、多基因同时表达调控等逻辑门基因线路设计。完成这些设计需要使用诱导型启动子、基于特定DNA序列靶向蛋白的启动子抑制、转录因子等转录调控工具。面对多基因的逻辑构建等复杂问题,手动设计时间成本高、准确性低,而基因线路自动化设计(GDA)可以快速将标准化基因元件组装和设计成具有所需功能的基因线路。
GDA基于标准化元件库,实现基因线路的数字化设计。研究人员使用合成生物学开放语言(SBOL)、系统生物学标记语言(SBML)等方法构建了SynBioHub、Addgene、iGEM等标准化基因元件数据库。基于这些数据库,开发了SBOLCanvas、iBioSim、Cello、SynBioSuite等GDA软件,实现基因线路快速精准数字化设计,其中Cello软件的基因线路设计在大肠杆菌、酵母菌、多形拟杆菌等细胞工厂中已有广泛的应用。
细胞工厂发酵工艺与过程数字化
获得高性能细胞工厂后,为使其能够实现目标产物工业规模发酵生产,需要将发酵体系逐级放大以优化发酵工艺与过程参数,实现产品的高效生产。面对生物发酵体系复杂、缺乏有效传感器、测样频率低、检测时间长导致时效性差等一系列问题,工业级发酵过程的数字孪生与优化控制有助于发酵体系的控制和产量的提高(图3)。
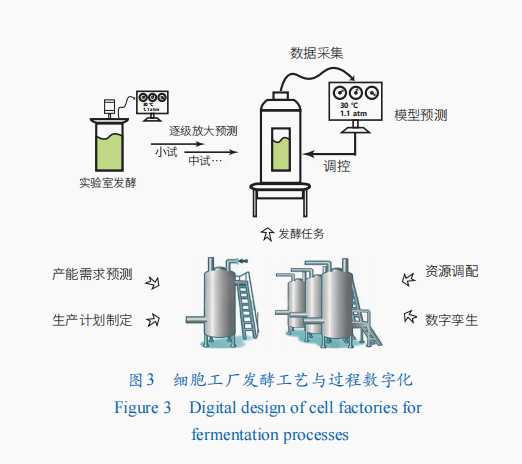
发酵体系放大及发酵过程控制数字化
在发酵工艺的设计过程中,放大效应的存在致使工艺设计与实际工业生产环境不匹配,影响细胞工厂合成效率。通过数字孪生,及其与知识图谱结合等数字化手段,可对发酵过程进行数字化模拟及实时监控,并对发酵过程进行自动化控制,实现发酵工艺的优化。
在发酵工艺中,数字孪生通过接受发酵过程产生的实时数据,如发酵体系溶氧(DO)、尾气分析、温度等,进行仿真、预测,分析发酵状态,并根据发酵状态对发酵体系进行优化和决策。通过人工智能,结合实际发酵体系,可以实现中试级别、生产级别发酵体系的数字孪生模型构建,并实现产物产量的提高。将基于关键因素间关系专家知识的知识图谱方法与数字孪生结合,构建两种方法的整合决策模型,可以提高预测准确性并增强控制性能。
发酵车间数字化管理系统设计
在工业生产中,设备、原料、人力等资源的时空调度同样是保证发酵工艺过程、工业生产效率的重要因素。在“工业4.0”的概念基础下,对工业生产过程进行信息化建设,构建企业资源计划(ERP)系统,并结合自动化系统,开发了制造执行系统(MES),实现数据实时采集、管理,并进行资源、设备的调度,构建发酵车间层次的管理数字化软件,实现了发酵过程成本降低及生产效率的提高。
数字细胞工厂总结与展望
基于人工智能、模型构建等的数字化方法已经在细胞工厂构建的全流程中得到了广泛的应用。相比传统细胞工厂设计方法,数字化设计具有高效、节约成本等优势。在以细胞工厂为核心的绿色生物制造高速发展的背景下,细胞工厂设计数字化进程正在不断加快,形成了包括数据库构建、细胞工厂代谢设计、发酵体系设计、发酵过程调控等的细胞工厂全生命周期数字化设计(图1)。随着未来计算能力的提升及更深入的学科交叉,全生命周期数字化细胞工厂设计将向更准确、更快速、更高效、全流程的方向发展,赋能绿色生物制造。
(作者:孟繁泽、秦磊,清华大学化学工程系 清华大学工业生物催化教育部重点实验室 清华大学合成与系统生物学中心;曹锐,新疆大学智能科学与技术学院;胡冰,北京理工大学化学与化工学院生物化工研究所;李春,清华大学化学工程系清华大学工业生物催化教育部重点实验室清华大学合成与系统生物学中心 北京理工大学化学与化工学院生物化工研究所。《中国科学院院刊》供稿)





