
Chip Learning:从芯片设计到芯片学习
|
|
中国网/中国发展门户网讯 芯片是现代信息社会的关键基础设施。绝大部分的电子设备——小到传感器、大到超级计算机,以及我们每天用的手机、电脑,都是建立在芯片基础之上的。从 20 世纪 60 年代开始,随着半导体工艺的发展,芯片的复杂度快速增加,从只有少数晶体管的小规模开始快速发展到千百万、数十亿晶体管规模。例如,2020 年英伟达(Nvidia)发布的 A100 芯片集成了 500 多亿晶体管。芯片制造工艺也已经接近量子领域,台积电(TSMC)的 5 nm 工艺已经开始量产芯片,英特尔(Intel)等厂商已经开展 2 nm 工艺的芯片研究。这些都离不开芯片设计的快速发展。
芯片设计本身是一个代价很高的过程。即使经过了 40 多年的发展,也集成了越来越多的先进算法,芯片设计仍然是一个周期非常长、过程非常复杂、对设计人员专业度要求很高的任务。芯片制造本身的高额费用也加剧了对于芯片设计的要求。通常整个芯片设计流程,从立项到最后交付流片,中间涵盖了逻辑设计、电路设计等复杂过程,大致需要 1—1.5 年的时间,需要包括系统设计人员、芯片设计人员、芯片开发人员、芯片验证和测试工程师在内的多名专业人员紧密地协作开发。
未来万物互联的智能时代需要大量不同种类的专用芯片。随着智能时代的到来和“摩尔定律”的大幅度放缓,专用芯片的数量和种类大幅度增加,芯片体系结构将要进入新的黄金时代,这对芯片设计提出了更大的挑战。目前,深度学习处理器芯片就有很多种。例如:国外,谷歌(Google)推出了 TPU,英伟达推出 DLA 和包含专用加速 TensorCore 的多款 GPGPU,英特尔收购了 Neverana、Movidius 等多家公司,ARM、高通(Qualcomm)、苹果(Apple)等公司的系统级芯片(SoC)也各自集成了自家的深度学习加速器硬件;国内,中科寒武纪科技公司推出了 Cambricon 云边端系列芯片,阿里巴巴公司推出了含光 NPU,华为公司推出了达芬奇架构芯片等。据统计,从 2014 年开始,全球深度学习处理器芯片就从一两款增长到了几百款之多。未来万物互联的智能时代对于大量种类和数量的芯片需求,也对芯片设计效率提出了新的挑战。
如何解决芯片设计需求多和芯片设计代价高之间的矛盾?其中,最关键的问题是芯片设计领域对设计人员的专业水平要求比较高,既包括专业知识,也包括从业设计经验。如果芯片设计的“门槛”能降下来,那么任何一个稍加培训的硬件设计人员就可以如同编写软件程序一样快速地完成芯片设计。本文提出芯片学习(Chip Learning)来取代芯片设计可解决上述矛盾,即采用学习的方法来完成芯片从逻辑设计到物理设计的全流程。简而言之,Chip Learning 针对这样一类问题:输入是简单的功能需求描述(或者芯片的硬件程序),而输出则是电路的物理版图。Chip Learning 通过学习已有芯片设计进行训练,根据输入生成满足要求的电路物理版图。我们希望 Chip Learning 学习到的模型在使用时完全不需要专业知识和设计经验,可以在短时间、无人参与的情况下完成芯片设计。本文首先介绍现有芯片设计的流程,同时介绍近几年人工智能(AI)技术在芯片设计中的应用,在此基础上说明实现 Chip Learning 的思路和面临的挑战。
芯片设计流程和 Chip Learning
芯片设计流程
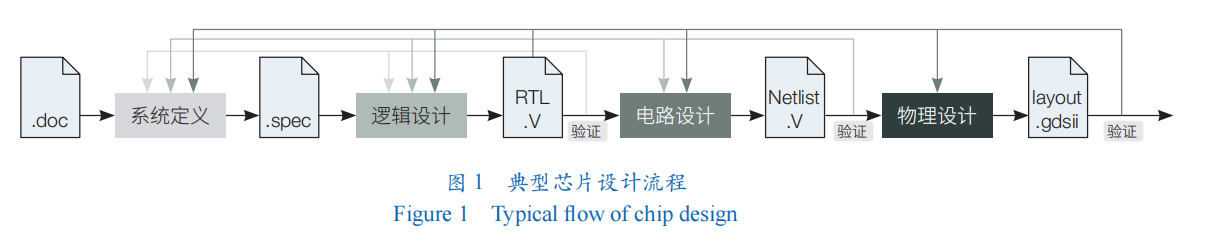
芯片设计是一个复杂的过程。通常,芯片设计指的是从需求出发最后生成版图(layout)的过程。典型的芯片设计流程可以被简单地划分成 5 个阶段(图 1):①系统定义(chip specification)。给定需求后,进入系统定义阶段,芯片设计人员确定设计参数,并完成包括结构、接口定义等具体设计。②逻辑设计(logic design)。由芯片开发人员根据系统定义进行逻辑设计,通常采用硬件开发语言 Verilog、VHDL 等实现芯片的硬件代码,包括其中各个功能模块、外部接口和整体连接。③电路设计(circuit design)。在得到芯片的硬件程序后,芯片开发人员进行电路设计,把硬件描述转换成为门级的电路表示。④物理设计(physical design)。在得到芯片网表之后,芯片开发人员进行物理设计,把门级网表转换成物理实现表示,即芯片的版图;其常见格式为图数据表示,即 graphic data systemⅡ(GDSⅡ)。另外,芯片开发人员会在物理设计的各个阶段进行验证测试和迭代设计,以得到符合需求的芯片设计。⑤验证测试(test & verification)。最终完成的芯片版图送至代工厂进行制造,后续再进封装、制板、测试等工序,这样就得到了一颗完整的芯片。
2. Chip Learning
近些年来,以深度学习为代表的 AI 技术再次兴盛,已经在很多任务上表现出卓越的效果。例如,ResNet-512 深度学习模型在图像识别上表现出超越人的识别能力,DeepMind 公司提出的 AlphaGo 系列模型在围棋游戏上表现超越人类棋力。研究人员也开始研究将最新的 AI 技术应用到芯片设计当中,如深度神经网络、强化学习、生成对抗网络等。这一方向也受到越来越多的关注。Cadence 公司已经在 2020 年发布了iSpatial 引擎,以支持机器学习进行统一布局布线和优化。Synopsys 公司也在 2019 年推出了 DSO.ai 工具,其基于 AI 技术极大地提升了芯片设计效率。
然而,目前全球芯片设计中的深度学习工作还主要停留在采用人工智能技术去辅助解决传统芯片设计流程中的子问题,如评估、预测芯片设计的结果等。与之不同的是,本文提出的 Chip Learning 技术内涵则是取代传统芯片设计流程,通过 AI 模型学习专业知识,从而实现无人化(no-man-in-the-loop)芯片设计(图 2)。具体而言,类比传统芯片设计流程,Chip Learning 可以分成 3 个重要问题:①功能生成。当用户用模糊的语言确定了系统功能,第一个重要的问题就是根据用户意图确定系统正确的功能,并生成系统的准确表达。这种准确表达可以是硬件代码,也可以是表达式,也可以是真值表。这个问题对应着传统芯片设计流程的逻辑设计。②逻辑图生成。当有了准确表达,第 2 个重要的问题就是要生成电路的逻辑图表达,并在这张逻辑图上进行优化,最后生成物理无关(包括工艺)的逻辑图表达。这个问题对应着传统芯片设计流程的电路设计。③物理图生成。当有了电路逻辑图后,第 3 个重要的问题就是要生成电路的具体物理版图,这等价于一种多种约束下(如面积、功耗、物理等限制)的图映射和优化问题。这个问题对应着传统芯片设计流程的物理设计。

芯片学习在芯片设计流程中需要解决的问题
逻辑设计
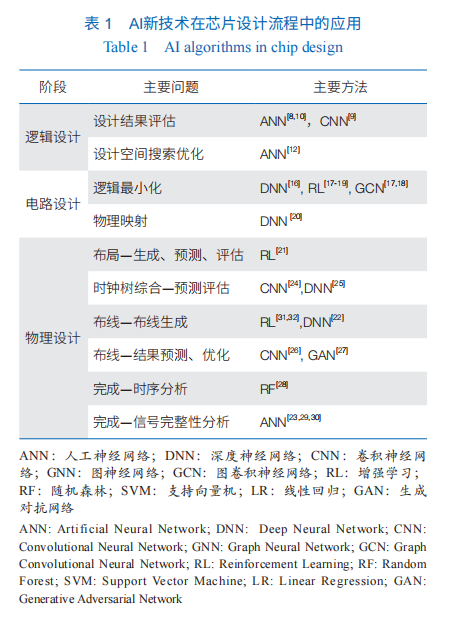
逻辑设计的核心就是要得到电路的硬件描述。通常这一过程通过人工完成,也就是硬件开发人员采用硬件描述语言如 Verilog、VHDL 手动编写 RTL 的硬件程序。还有一种方法就是高层次综合(HLS)。高层次综合指的是通过高层次综合工具把 C、C++或者 SystemC 等高级编程语言描述的硬件功能转化成为硬件描述语言 Verilog、VHDL 程序。传统高层次综合算法一般通过确定性的方法对高级语言进行变换。近些年来,除了传统的机器学习算法如支持向量机(SVM),最新的人工智能技术如深度神经网络(DNN)、图神经网络(GNN)也被用于高层次综合中,主要用于帮助更快速的 HLS 设计结果评估(质量估计、性能估计、时序估计、资源开销估计)和 FPGA 设计空间搜索优化。
与上述 2 种方法相比,芯片学习更进一步:当用户给定模糊描述后,通过猜测用户意图自动编写硬件程序,或者说自动生成硬件的准确表达——可以是硬件 RTL 程序,也可以是硬件表达式,还可以是硬件真值表。这其中面临很多挑战,如用户意图的确定,硬件表达的准确性等。在该方面,程序综合(program synthesis)——自动构建由指定语言构成的、符合用户某种要求的程序,跟芯片学习的功能确定问题具有同样的形式。目前,程序综合已经有了很多进展可供芯片学习借鉴参考。
电路设计
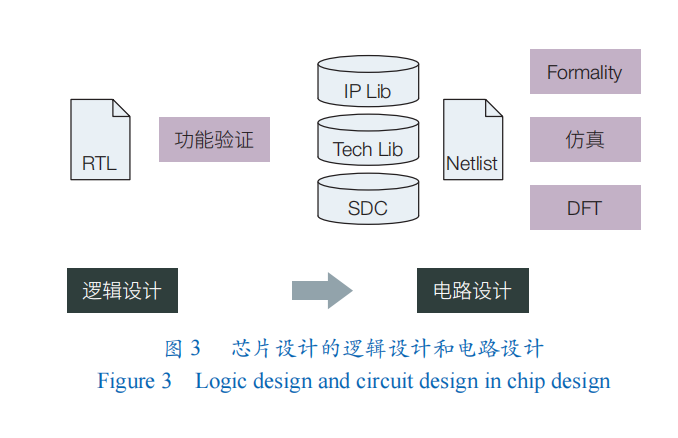
在得到芯片的硬件描述后,芯片开发人员进行电路设计。如图 3 所示,在电路设计中,电路的硬件描述程序会被转化成为电路图(网表),这个过程也被称为前端设计(front-end processing)或者综合(synthesis)。
电路设计包含 2 个核心优化步骤:逻辑最小化和物理映射。逻辑最小化指对电路的布尔表达式和逻辑网表结构进行化简,从而得到尽可能小的逻辑表达式。物理映射则是在给定物理工艺库的情况(如可用的门的种类、标准单元),把逻辑表达式映射到这些物理单元上,生成尽可能简单的物理电路。当前,芯片设计中利用 AI 技术可实现的相关工作主要集中在这 2 个核心优化步骤上。LSOracle 采用深度神经网络(DNN)去动态决定电路中不同部分是采用 And-Inverter Graph 还是 Majority-Inverter Graph 优化器。Haaswijk等和Zhu等把逻辑优化问题定义成马尔可夫决策过程(Markov decision process),采用深度强化学习框架,图卷积神经网络作为策略,来实现逻辑优化。Hosny 等则采用强化学习里的演员-评论家模型(A2C)来寻找时序约束下最小化面积开销的逻辑最小化方案。Deep-PowerX 通过 DNN 来预测部分电路采用近似电路时的电路输出错误率,从而尽可能地降低电路的动态功耗。
芯片学习在这个阶段要解决的问题是逻辑图生成,也即在给定电路的硬件描述(如 RTL 程序、表达式或真值表)和可用节点类型的约束下,生成电路相应的逻辑图。在该逻辑图中,节点是门、宏单元、已知功能模块,连线是有方向的,表示信号从一端流向另外一端。如果是时序电路,逻辑图中还会存在环路。同样的,在该逻辑图上需要做优化,以尽可能地去掉电路中的冗余,保证生成的逻辑图尽量精简。一个思路是采用传统编译的思路完成这个过程,并采用上文类似的 GNN 和增强学习(RL)方法实现图级别优化。另外一个思路是采用神经编译器(neural compiler),直接替代传统的编译技巧,把输入转化成为逻辑图并在图上做进一步的优化,从而得到更简洁的逻辑图表达。
物理设计
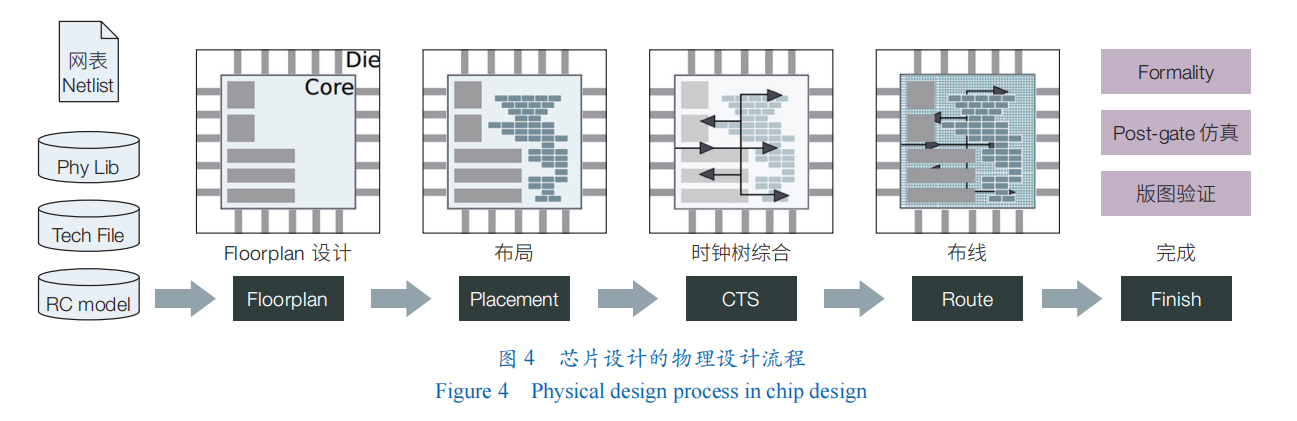
在得到芯片网表之后,芯片开发人员开始进行物理设计;其把门级网表转换成物理元器件及其连线并固定下来,最后得到芯片的版图。物理设计流程比较复杂(图 4),不同工艺还有其独特的地方,主要包括 floorplan 设计、布局(placement)、时钟树综合(CTS)、布线(route)、完成(finish)。在开始物理设计之前,设计人员需要先确定物理设计环境,包括设计所需要的物理库(physical library)、工艺(technology file)、设计约束库(constraints file)等;芯片设计相关的参数,包括设计采用的工艺、芯片采用几层金属、最小线间距、所允许的最大扇出(fanout)等。
物理设计本身流程多、复杂,子问题也多,因此采用AI技术解决其中子问题的研究工作也相对多一些。在布局中,AI 技术主要被用来生成更好的布局和预测布局后的结果。例如,在 2021 年发表的电路后端设计自动化的工作中,谷歌把布局问题形式化为序列决策问题,从而利用强化学习的方法来解决,不到 6小时即可生成具有媲美或超过人工的现代加速器网表上的布局。He 和 Bao使用强化学习训练一个 Agent 帮助选择空间搜索时下一步访问的邻居节点,用以指导生成更好的布局。在时钟树综合中,AI 技术的应用主要关注对生成的时钟树做优化或预测。Lu 等提出采用生成对抗网络(GAN)和强化学习来预测、优化生成的时钟树,从而降低时钟漂移和时钟树长度。Nagaria 和 Deb、Kwon等分别采用卷积神经网络(CNN)、DNN 来预测时钟树组件,如 gatingg 单元、buffer 数量、wireloads 等,从而帮助提高时钟树质量,降低时钟树长度、时钟漂移等。在布线中,人工智能技术主要被用来布线结果预测和评估。Liang等和Alawieh等将问题化为 image-to-image 问题,分别用 CNN 和条件生成对抗网络(CGAN)进行布线堵塞预测。在完成阶段,AI 技术主要用于验证测试中的时序分析、信号完整性分析和功耗分析方面。Barboza等用随机森林方法使时序分析可以脱离手工特征进行,同时减小布线前时序估计的误差。Ambasana等、Lu等、Goay 和 Goh的多篇工作都以眼图的宽高用神经网络为基础预测电路信号串扰或抖动。
芯片学习对应的子问题是物理图生成。可以看到,在物理设计的多个阶段,AI技术被广泛地用来辅助解决其中的子问题,芯片学习则期望能够直接端到端得到一个最终的物理版图。这个子问题的难度可想而知,其中涵盖了多个子问题,也极有可能需要多个模型协同进行工作,才有可能最终解决。利用芯片学习端到端得到最终物理版图的挑战主要有 2 个方面:①问题和约束形式化较为困难。正如上面芯片物理设计流程中所介绍的一样,问题本身的输入是类似网表的逻辑图,最终输出的是物理版图。不同规模的电路蕴含的功能也不一样,这就意味着统一的模型能够处理变长、变规模的输入和输出。另外,物理设计中的约束也是多种多样的,包括:芯片本身的最大面积、所能容忍的最大延迟等基本约束,以及电源网络构建、crosstalk 消除、天线效应等约束。这些约束需要变成结构化的信息从而可以被人工智能模型所接受,也即计合理的数据结构,这也是非常困难的。②问题对应的解空间规模大。电路物理设计过程中本身就包含了很多复杂度很高甚至于是 NP 完全问题,这也就意味着物理设计本身是一个随着规模增大复杂度急剧上升的问题。
对于解决芯片学习物理版图生成这个非常困难的问题,目前已经看到了一些曙光。谷歌使用 RL 和GNN 替代了传统的布局过程,Liao等、He和Bao也提出了直接替代布线过程的小规模电路上的方案,从而证明了 AI 技术在传统问题上大有可为。物理版图最终是要针对工艺的,而值得庆幸的是,现在芯片设计流程中的设计规则是抽象出来与工艺无关的约束规则,这也将是芯片学习解决方案未来能够泛化到不同工艺上的基础。
验证测试
验证测试贯穿整个芯片设计流程。在不同阶段,芯片开发人员都需要对得到的设计进行反复验证,如功能测试验证、逻辑测试验证、电路测试验证、网表测试验证、版图测试验证。
对于芯片学习而言,验证测试核心要解决的挑战就是黑盒解决方案的精度保证。现有的 AI 技术虽然能在很多问题上达到很好的效果,但其为人所诟病的一点就在于这些黑盒模型缺乏可解释性,对于输出结果的精度也无法给出理论的保证。这一点对于芯片学习尤其重要,因为芯片流片的成本非常高,即使未来在工程上芯片学习能够解决问题,AI 新技术的可解释性也需要继续深入研究。
未来工作
芯片学习是万物互联的智能时代解决芯片设计需求大和代价高之间矛盾的核心方法。目前,AI 新技术在芯片设计流程中已经得到应用(表1),然而这些工作都还是集中在芯片设计各个环节当中的子问题,主要是辅助传统设计流程,完成预测、评估方面的功能,尚未实现 AI 取代传统芯片设计流程;芯片学习则是希望能够完全取代传统芯片设计流程,用 AI 模型学习专家知识,大幅度降低芯片设计门槛,提升芯片设计效率,从而实现端到端的快速无人化芯片设计。
芯片学习未来有 3 点主要工作。全流程。芯片学习在各个流程上实现取代传统算法,同时在各个流程中消除人的参与,从而实现芯片设计全流程无人化以节省人力资源,实现高效率的芯片设计。跨层次优化。利用芯片学习,希望将芯片设计各个环节打通实现跨层次设计与优化,实现大规模芯片统一设计,从而实现更优的芯片设计。并行加速。AI 技术以计算量大、数据量大著称,而芯片设计又是非常复杂的任务,芯片学习也需要研究并行和加速方法。例如,采用已经蓬勃发展的人工智能芯片,从而保证芯片设计效率。未来,芯片学习希望实现从设计芯片到自动生成芯片的转变,更好地支撑智能万物互联时代的应用需求。
(作者:陈云霁,中国科学院计算技术研究所 计算机体系结构国家重点实验室、中国科学院大学 计算机科学与技术学院;杜子东、郭崎、李威,中国科学院计算技术研究所 计算机体系结构国家重点实验室;谭懿峻,中国科学院计算技术研究所 计算机体系结构国家重点实验室、中国科学院大学 计算机科学与技术学院;《中国科学院院刊》供稿)