
科学大数据管理技术与系统
|
|
科学大数据管理引擎
BigSDMS 包括 3 类科学大数据管理引擎:大规模图数据管理、大规模半结构数据管理和大规模关系型数据管理。其中,大规模图数据库 Gstore 支持 100 亿条三元组图数据管理和秒级查询响应时间。大规模半结构化数据库 Eventdb 支持万亿级高能物理实验事例、EB 量级数据管理能力。大规模关系型数据库 AstroSever 支持千亿行天文星表数据的管理,大、中、小规模数据典型操作的查询优化及满足数据处理精度与实时性的要求。这 3 类数据库基本满足了目前常见科学实验中大规模数据的存储、访问等管理需求。
科学大数据系统集成
BigSDMS 集成包含弹性部署(EMR)、流水线(Piflow)、融合查询(Simba)和数据共享(Pishare)4 个部分。其中,EMR 的弹性伸缩方案综合使用渐进式伸缩和定量式伸缩的优点:当负载模型可信度低于阈值时,采用渐进式方法进行伸缩,并根据扩容后的资源竞争修正负载模型;若负载模型可信度达到阈值后则采用定量式伸缩方法。Piflow 基于 Petri 网,处理单元(processor)在未知状态(unknown)、活跃状态(active)、休眠状态(hibernated)3 种状态之间进行转换,完成流程的执行与监控。Simba 基于 Sparksql,在 Zeppelin 可视化界面中通过 SQL 查询进行多种数据源的融合查询分析。Pishare 基于开源区块链项目 Hyperledger,在区块链上 Pishare 会对数据进行加密存储和产权认证,并通过积分机制(科学币)对数据提供者进行奖励以及数据市场的交易。
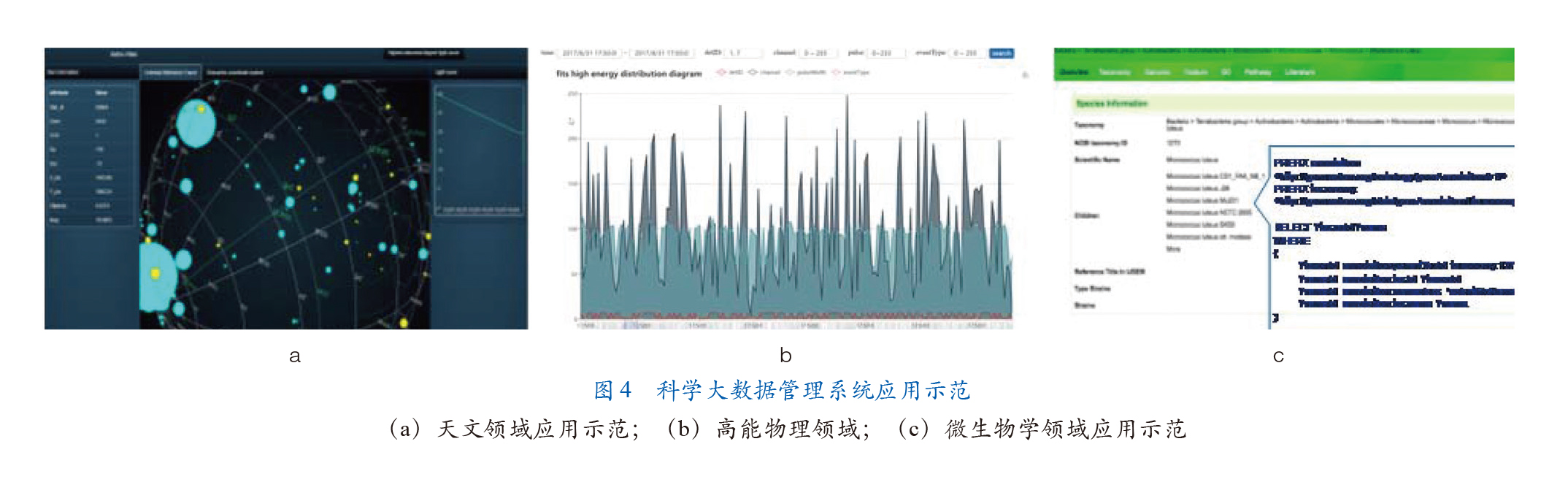
科学大数据应用示范
目前,基于 BigSDMS,我们在天文学、高能物理、微生物学领域构建了 3 个应用示范:①天文学领域使用了 100 亿行星表数据,定义了 5 个光变曲线处理流程,实现 680 万行星表数据插入时间少于 3 s,“异常发现”时间小于 1 s(图 4a);②高能物理领域使用了 BESIII 产生的 942.9 亿条事例数据,相对于业界常用的 Boss 查询平均查询效率提高 10 倍以上(图 4b);③微生物学领域整合了 200 种微生物种菌信息,构建了 5 亿条规模的 RDF 知识图谱数据(图 4c)。
随着人类对客观世界的深入认知,越来越多的社会和自然现象能够通过观测设备进行量化,这将导致科学数据的体量和类型持续增加。在数据驱动的科学发现模式下,应对科学大数据管理的 SPUS 挑战已成为眼下刻不容缓的任务。由中国科学院计算机网络信息中心牵头的国家重点研发计划“科学大数据管理系统”项目对这些问题进行了深入探索,研发了一套科学大数据管理系统 BigSDMS。未来我们还会在弹性部署、流水线、数据融合和数据发布共享 4 个方面进行更深入的探索,如竞争度的量化与预测、流水线中间数据模型设计、多查询引擎的 Polystore 方式集成、数据共享机制优化等。随着科学大数据管理技术和系统研究不断深入,科学大数据对科学发现的贡献将会越来越大!(作者:黎建辉 李跃鹏 王华进 陈明奇 中国科学院计算机网络信息中心北京 中国科学院大学北京 中国科学院办公厅北京。《中国科学院院刊》供稿)